dhd-blog
Stellenausschreibung Doktorandenstelle DH Graz
Universitätsassistent:in ohne Doktorat (m/w/d)
Bewerbungsfrist: 22.10.2024
Verwendungsgruppe: B1 ohne Doktorat
Brutto Jahresgehalt (Vollzeit): € 50.103,20
Dienstbeginn: Februar 2025
Wochenstunden: 30 h/W
Anstellungsdauer: Befristet
Befristung: 4 Jahre
Ihre Aufgaben
Forschung und Lehre im Fachbereich Digital Humanities
Mitwirkung an Forschungsvorhaben des Instituts für Digitale Geisteswissenschaften
Die im Rahmen der Stelle durchgeführte Forschungsarbeit soll in einer Dissertation im Fachbereich Digital Humanities münden
Selbstständige Abhaltung von Lehrveranstaltungen sowie Mitarbeit bei Lehr- und Prüfungsaufgaben des Instituts
Betreuung von Studierenden
Mitarbeit an Organisations- und Verwaltungsaufgaben sowie an Evaluierungsmaßnahmen
Ihr Profil
Abgeschlossenes Master- oder Diplomstudium in Digital Humanities oder einem anderen geisteswissenschaftlichen Fach, einem Fach mit Informatikbezug, im Zuge dessen Sie sich auch mit geisteswissenschaftlichen Fragen und Methoden beschäftigt haben
Sicherer Umgang mit komplexen Anwendungen zur Erzeugung, Verwaltung, Auswertung oder Visualisierung von geisteswissenschaftlichen Daten
Fließende Sprachkenntnisse in Englisch und Deutsch. Falls Sie zum Zeitpunkt der Einstellung noch unzureichende Deutschkenntnisse besitzen, beabsichtigen Sie im Laufe Ihrer Tätigkeit Ihre deutschen Sprachkenntnisse auf Niveau C1 auszubauen
Grundlegende Kenntnisse in mindestens einer der folgenden Technologien, nachgewiesen durch Beispiele selbstgeschriebenen Codes (X-Technologien, Python, HTML/CSS/JavaScript, Semantic Web Stack, R, Java)
Erfahrung in der Umsetzung und Durchführung von Projekten aus dem Fachbereich der Digital Humanities (wünschenswert)
Kommunikations-, Organisations- und Teamfähigkeit
Für eine vollständige Bewerbung sind folgende Unterlagen notwendig:
Motivationsschreiben und akademischer Lebenslauf
Vollständiger Nachweis über den Abschluss des in der Ausschreibung geforderten Studiums
Im Curriculum geforderter Sprachnachweis, sofern das Doktoratsstudium nicht in der Erstsprache absolviert wird.
https://jobs.uni-graz.at/de/jobs/30fb42f7-aab5-6d45-9770-66d1817c62e7
Call for Abstracts: LLM fails – Failed experiments with Generative AI and what we can learn from them
**automatic English translation below**
Workshop am 8. und 9. April 2025 im Leibniz-Institut für Deutsche Sprache, Mannheim
Visit our Workshop-Website to stay up-to-date.
Organisation: Annelen Brunner, Christian Lang, Ngoc Duyen Tanja Tu
Gescheiterte Experimente finden für gewöhnlich keinen Platz im wissenschaftlichen Diskurs, sie werden verworfen und nicht publiziert. Wir glauben, dass dadurch potenzieller Erkenntnisgewinn verloren geht. Schließlich ermöglicht eine systematische Reflexion über die Gründe des Scheiterns, angewendete Methoden zu hinterfragen und/oder zu verbessern. Zudem kann bei der Wiederholung zuvor gescheiterter Experimente explizit Fortschritt ermittelt werden, wenn diese dann gelingen. Die Diskussion und Dokumentation von Fehlschlägen schafft somit aus Perspektive der Methodenreflexion einen Mehrwert für die wissenschaftliche Gemeinschaft. Dies gilt umso mehr in einem Bereich wie der Forschung zu und mit Generativer Künstlicher Intelligenz, die nicht auf eine jahrzehntelange Tradition zurückblicken kann und in dem Best Practices erst ausgehandelt werden.
In diesem Workshop stehen linguistische und NLP-Experimente mit Generativer Künstlicher Intelligenz im Fokus, die nicht die gewünschten Ergebnisse gebracht haben, beispielsweise, aber nicht beschränkt auf:
- Einsatz einer Generativer KI als Named-Entity-Recognizer
- Einsatz einer Generativer KI zur automatischen Transkription von gesprochenen Sprachdaten
- Einsatz einer Generativer KI zur Erstellung von Wörterbuchartikeln
- Einsatz einer Generativen KI zur Detektion von Sprachwandelphänomenen
Im Beitrag sollte klar werden, inwiefern dieses Scheitern zum Erkenntnisgewinn bezüglich der Arbeit mit Generativer KI beitragen kann.
Unveröffentlichte Beitragsvorschläge können bis zum 02.12.2024 in Form eines Abstracts (500-750 Wörter) in deutscher oder in englischer Sprache anonymisiert an folgende Mailadresse gesendet werden:
Über die Annahme der Beiträge entscheidet das Organisationsteam bis zum 16.12.2025. Bei Annahme des Beitrags wird die Ausarbeitung zu einem short paper (4-6 Seiten ohne Referenzen) auf Englisch bis zum 15.02.2025 erbeten. Es ist geplant, die angenommenen short paper zu veröffentlichen.
Der Workshop findet vom 8.-9.4.2025 (Lunch-to-Lunch) am Leibniz-Institut für Deutsche Sprache in Mannheim statt. Die 20-minütigen Vorträge können auf Deutsch oder Englisch gehalten werden.
Call for Abstracts (English)Failed experiments typically have no place in scientific discourse; they are discarded and not published. We believe this leads to a loss of potential knowledge. After all, a systematic reflection on the reasons for failure allows for the questioning and/or improvement of methods used. Furthermore, when previously failed experiments are repeated and succeed, explicit progress can be determined. Thus, the discussion and documentation of failures creates added value for the scientific community from the perspective of methodological reflection. This is even more relevant in a field like research into and with Generative Artificial Intelligence (AI), which cannot look back on decades of tradition and where best practices are still being negotiated.
This workshop focuses on linguistic and NLP experiments with Generative AI that did not yield the desired results, such as but not limited to:
- Using Generative AI as a Named-Entity Recognizer
- Using Generative AI for automatic transcription of spoken language data
- Using Generative AI for the creation of dictionary entries
- Using Generative AI for the detection of language change phenomena
The contribution should clarify how this failure can contribute to knowledge gain regarding the work with Generative AI.
Unpublished proposals can be submitted anonymously as an abstract (500-750 words) in either German or English to the following email address by December 2, 2024:
The organization team will decide on the acceptance of contributions by December 16, 2025. If a contribution is accepted, a short paper (4-6 pages without references) in English will be requested by February 15, 2025. The accepted short papers are planned to be published.
The workshop will take place from April 8-9, 2025 (Lunch-to-Lunch) at the Leibniz Institute for the German Language in Mannheim. The 20-minutes presentations can be given in either German or English.
Important dates:Deadline Abstract: December 2, 2024
Notification: December 16, 2025
Deadline short paper: February 15, 2025
Workshop: April 8-9, 2025 (Lunch-to-Lunch) at the Leibniz Institute for the German Language, Mannheim
{kind=link}
generated with GPT-4o
Verstärkung gesucht: Bereich Open Access
Die Landesbibliothek Oldenburg versorgt als stark frequentierte wissenschaftliche Gebrauchsbibliothek in zentraler Lage die Bevölkerung der Region Oldenburg mit wissenschaftlicher Literatur. Sie sammelt, erschließt und archiviert als Landes- und Regionalbibliothek das Schrifttum über Nordwestniedersachsen und erhält, erforscht und digitalisiert als viertgrößte Altbestandsbibliothek in Niedersachsen ihre umfangreichen historischen Buchbestände, Handschriften und Sondersammlungen.
In der Landesbibliothek Oldenburg ist ab dem 01.11.2024 ein befristeter Arbeitsplatz in Teilzeit (50%) für einen/eine
Wissenschaftliche*n Mitarbeiter*in (m/w/d)
im Bereich Open Access
zu besetzen. Der Arbeitsplatz ist nach EG 13 TV-L bewertet. Die Stelle ist zunächst auf zwei Jahre befristet. Vorbehaltlich der Bewilligung zusätzlicher Projektmittel besteht voraussichtlich ab dem 01.12.2024 die Möglichkeit, die Stelle auf Vollzeit (100 %) aufzustocken.
Ihre Aufgabe ist es,
die Landesbibliothek Oldenburg beim Aufbau von neuen Geschäftsprozessen, Dienstleistungen und Angeboten im Bereich Open Access (OA) zu unterstützen, z.B. durch
- Auswahl von OA-Angeboten für Nutzer*innen
- Beratung von Wissenschaftler*innen zu OA-Publikationsmöglichkeiten u.a. im Rahmen des Projekts „NiedersachsenOpen“
Im Falle einer Stundenaufstockung aus Projektmitteln kämen folgende Aufgaben hinzu:
- Statistische Auswertung und wissenschaftliche Bewertung von OCR-Erkennungsergebnissen (Optical Character Recognition) in der Zeitungsdigitalisierung
- Prozessoptimierung auf organisatorischer Ebene (in Zusammenarbeit mit der
IT-Abteilung und kommerziellen Dienstleistern)
Ihr Profil:
Sie passen zu uns, wenn Sie über ein abgeschlossenes wissenschaftliches Hochschulstudium (Master oder gleichwertig) in einem relevanten Fachgebiet verfügen. Außerdem sollten Sie folgende Qualifikationen und Fähigkeiten mitbringen:
- Interesse an der digitalen Transformation im Wissenschaftsbereich
- Kenntnisse im Bereich Open Access
- Affinität zu digitalen Tools und Bereitschaft zur Einarbeitung in statistische Auswertungstechniken
- wünschenswert wären Erfahrungen in Projektarbeit, vorzugsweise im wissenschaftlichen Umfeld
- gute Kommunikationsfähigkeiten sowie Freude daran, komplexe Inhalte verständlich zu vermitteln
- selbstständige, strukturierte und zielorientierte Arbeitsweise
- Teamfähigkeit, Flexibilität und ein hohes Maß an Eigeninitiative
Wir bieten Ihnen
- ein interessantes und abwechslungsreiches Arbeitsumfeld in einer bürgernahen, wissenschaftlichen Landeseinrichtung
- die Chance, aktiv an der Gestaltung der digitalen Transformation in der Landesbibliothek Oldenburg mitzuwirken
- einen Arbeitsort in zentraler Lage in Oldenburg mit direkter Anbindung an den ÖPNV
- ein gutes, kollegiales Arbeitsklima und einen modern ausgestatteten Arbeitsplatz
- flexible Arbeitszeitmodelle zur besseren Vereinbarkeit von Beruf, Familie und Freizeit
- Entwicklungs- und Fortbildungsmöglichkeiten
- eine jährliche Jahressonderzahlung nach dem TV-L und eine zusätzliche betriebliche Altersvorsorge (VBL)
Weitere Besonderheiten:
Die Landesbibliothek Oldenburg ist bestrebt, den Frauenanteil im bibliothekarischen Bereich zu erhöhen. Bewerbungen von Frauen werden daher ausdrücklich begrüßt.
Schwerbehinderte Bewerbende werden bei gleicher Eignung bevorzugt berücksichtigt. Zur Wahrung Ihrer Interessen bitten wir Sie bereits in der Bewerbung mitzuteilen, ob eine Schwerbehinderung oder Gleichstellung vorliegt und Ihrer Bewerbung eine Kopie des Schwerbehindertenausweises bzw. Gleichstellungsbescheides beizufügen.
Wir freuen uns über Bewerbungen von Menschen mit Migrationshintergrund.
Ihre Ansprechperson:
Bitte richten Sie Ihre aussagefähige Bewerbung bis zum 20.10.2024 als eine Gesamt-PDF-Datei per E-Mail an “roeder@lb-oldenburg.de“ oder in schriftlicher Form an die Landesbibliothek Oldenburg, Pferdemarkt 15, 26121 Oldenburg.
Eingereichte Bewerbungsunterlagen werden grundsätzlich nicht zurückgesandt und nach drei Monaten vernichtet.
Bei Rückfragen zum Bewerbungsverfahren sowie zum Arbeits- und Aufgabengebiet können Sie sich auch vorab bei Herrn Dr. Matthias Bley (Abteilungsleiter Digitale Bibliothek) unter 0441/505018-63 informieren.
Workshop: Exploring Connections. A Bring Your Own Data Lab on Historical Network Analysis (17./18.10.)
Designed for researchers in the humanities and cultural sciences, this workshop of the DH Lab of the Leibniz Institute of European History (IEG) as part of the Data Competence Centre HERMES – Humanities Education in Research, Data, and Methods offers a practical, supportive and cooperative space to deepen knowledge of Historical Network Analysis. By the end of the Bring Your Own Data Lab, participants will be able to apply more confidently network analysis methods to their own data sets.
Date and Place:17.-18.10.2024 at the Leibniz Institute of European History (IEG), Mainz
Aims and Contents:This workshop focuses on the application of network analysis to historical research, offering a hands-on opportunity for participants to engage with their own datasets. Through interdisciplinary collaboration and expert guidance, we will explore how network analysis can be used to uncover connections, patterns, and relationships within historical data. The workshop will provide insights into both the methodological challenges and the opportunities that arise when applying digital tools to historical inquiry, fostering a dynamic exchange between academics and practitioners in the field.
The current programme and additional details can be found here.
Preparation and Prerequisites:- Basic programming knowledge (R, Python, …). Note that the course will be in Python. On the Leibniz-Institute of European History GitHub repository you can access some preparing material (Python programming, Data Analysis with Python): There are 2 Jupyter Notebooks: Introduction_Jupyter_Python.ipynb and Intro_Data_Analysis_with_Python.ipynb. There is also a Jupyter Notebook assignment.ipynb if you want to check your understanding (the document is not long, you may need < 1h).
- Willingness to learn new technical skills
- Important: install and get comfortable with Anaconda3. It contains all packages we will need (Jupyter notebooks included):
> Installing Anaconda > Setting up a new environment, e.g. “HNR” > Installing networkX-package, pandas, matplotlib
- Dr Judit Garzón Rodríguez (hermes@ieg-mainz.de)
- Registration is open until October 14, 2024
- Please register early, as the number of places is limited to 15 participants
Federal Ministry of Education and Research (BMBF)
Funded by the European Union – NextGenerationEU
Stellenausschreibung: Softwareentwickler/in (m/w/d) am Deutschen Historischen Institut in Rom
sucht für den Forschungsbereich Digital Humanities zum 1. Januar 2025 für einen befristeten Zeitraum von drei Jahren
eine*n wissenschaftliche*n Mitarbeiter*in (w/m/d) mit dem Schwerpunkt Softwareentwicklung
Das DHI Rom ist eine Einrichtung der in Bonn ansässigen Max Weber Stiftung – Deutsche Geisteswissenschaftliche Institute im Ausland. Es widmet sich der epochenübergreifenden, interdisziplinären Erforschung der italienischen und deutschen Geschichte und Musikgeschichte in ihren europäischen und globalen Bezügen vom Mittelalter bis heute.
Das innerhalb des e-research-Programms von der DFG zunächst für 3 Jahre geförderte Forschungsprojekt „Forschungsdateninfrastruktur Historische Quellen (HisQu)“ zielt darauf ab, neue Methoden und eine innovative digitale Infrastruktur zur semantischen Erschließung historischer Quellen zu entwickeln. In Zusammenarbeit mit renommierten Partnerinstitutionen wird dafür eine Plattform aufgebaut, die es ermöglicht, historische Forschungsprozesse digital gestützt, nachvollziehbar und reproduzierbar zu gestalten.
Im Rahmen dieses Vorhabens soll die bestehende Dateninfrastruktur des „Repertorium Germanicum“ (RG) weiterentwickelt und durch die in HisQu entstehenden Services ergänzt werden. Das RG ist ein Grundlagenforschungsprojekt des DHI Rom, das sich u. a. mit der digitalen Erschließung und Analyse von Quellen zur Geschichte der mittelalterlichen Kirche beschäftigt.
Ihre Aufgaben:
- Weiterentwicklung der bestehenden RG-Infrastruktur und Webanwendung
- Implementierung und Integration neuer Services, die die Erschließung, Modellierung, Analyse und Visualisierung der erfassten Daten unterstützen
- Zusammenarbeit mit Entwicklerteams und Fachwissenschaftler*innen
- Dokumentation der Entwicklungsprozesse und Publikation der Forschungsergebnisse
- Präsentationen auf nationalen und internationalen Tagungen
Ihre Qualifikation:
- Ein abgeschlossenes Masterstudium in Informatik, Digital Humanities, Informationswissenschaften oder einem verwandten Bereich
- Sehr gute Kenntnisse im Bereich der Full-Stack-Webentwicklung, insbesondere in Bezug auf die Entwicklung von grafischen Benutzeroberflächen und Daten-Schnittstellen
- Idealerweise Kenntnisse von Standards aus dem Bereich des Semantic Web (RDF, SPARQL)
- Interesse an der Anwendung moderner Technologien in der historischen Forschung
- Selbstständige und strukturierte Arbeitsweise sowie Kommunikations- und Teamfähigkeit
- Gute Kenntnisse der deutschen Sprache werden vorausgesetz
Wir bieten:
- Eine anspruchsvolle und vielseitige Tätigkeit in einem innovativen Forschungsprojekt
- Die Zusammenarbeit mit einem interdisziplinären Team von Historiker*innen, Informatiker*innen und (digitalen) Geisteswissenschaftler*innen
- Ein familienfreundliches Arbeitsumfeld und die Möglichkeit zur flexiblen Einteilung Ihrer Arbeitszeit
Bei Vorliegen der entsprechenden Voraussetzungen wird eine Vergütung nach der Entgeltgruppe 13 des TVöD zzgl. Auslandsbezüge nach den Bestimmungen des Bundesbesoldungsgesetzes und ggf. Umzugskostenerstattung nach den Bestimmungen des Bundesumzugskostengesetzes geboten. Alternativ kann auch eine Eingruppierung auf Grundlage der Vergütungstabelle der Deutschen Botschaft Rom gem. Livello AA2 in Höhe von derzeit mindestens 3.883,96 € brutto pro Monat Grundgehalt erfolgen, sollten die Voraussetzungen für eine Entsendung und/oder befristete Beschäftigung nach dem WissZeitVG nicht (mehr) möglich sein. Dienstort ist Rom.
Der Max Weber Stiftung liegt die Vereinbarkeit von Beruf und Familie am Herzen. Wir setzen gleichstellungspolitische Ziele und Vorgaben um und fordern qualifizierte Frauen nachdrücklich auf, sich zu bewerben. In unseren Auswahlverfahren wägen wir die individuellen Belange aller Bewerber*innen sorgfältig ab und besetzen die ausgeschriebene Stelle bei gleicher Eignung, Befähigung und fachlicher Leistung nach Maßgabe des Bundesgleichstellungsgesetzes. Wir wertschätzen Vielfalt und begrüßen daher alle Bewerbungen unabhängig von Nationalität, ethnischer und sozialer Herkunft, Religion und Weltanschauung, Alter sowie sexueller Orientierung und Identität. Erste Informationen zu den Lebens- und Arbeitsbedingungen am Dienstort Rom finden Sie auf unserer Webseite.
Bewerbungen mit den üblichen Unterlagen werden bis zum 27.10.2024 ausschließlich über unser Bewerbungsportal entgegengenommen. Bitte reichen Sie keine eigene Projektbeschreibung ein. Die Bewerbungsgespräche finden online statt und sind für Mitte November 2024 vorgesehen.
Ansprechpartner für Rückfragen: Jörg Hörnschemeyer, hoernschemeyer(at)dhi-roma.it.
Aktenzeichen: VN 107/2024
Die Koordinationskomitees von Text+ werden neu gewählt
Die zweijährlich stattfindenden Wahlen der Koordinationskomitees von Text+ stehen an. Der Wahltermin ist der 6. November 2024. Die Wahl wird über ein elektronisches System erfolgen und eine Stimmabgabe vom Wahltermin bis zum 13. November 2024 ermöglichen.
Die Koordinationskomitees (https://text-plus.org/ueber-uns/governance/) sind die zentralen Mitbestimmungsgremien der Text+ Communitys. Sie setzen sich aus drei verschiedenen Scientific Coordination Committees, die jeweils für eine der Datendomänen (Collections, Editions, Lexical Resources) zuständig sind, und einem Operations Coordination Committee zusammen. Ihre Aufgabe ist es, kontinuierlich das Portfolio an Daten, Werkzeugen und Services zu evaluieren und zu erweitern. Die Koordinationskomitees setzen sich aus Expertinnen und Experten der jeweiligen (Fach-)Domänen zusammen und werden alle zwei Jahre gewählt.
Gewählt werden die folgenden Komitees von Text+:
- Scientific Coordination Committee für die Task Area Collection
- Scientific Coordination Committee für die Task Area Lexical Resources
- Scientific Coordination Committee für die Task Area Editions
- Operations Coordination Committee für die Task Area Infrastructure/Operations
Wir laden Sie herzlich ein, bis zum 23. Oktober 2024 eine oder mehrere Personen für eines (oder mehrere) dieser Komitees zu nominieren, unter Angabe der Kontaktinformationen der nominierten Person. Auch Selbstnominierungen sind möglich. In jedem Komitee ist ein Sitz für eine Person aus dem wissenschaftlichen Nachwuchs reserviert; wir bitten daher auch ausdrücklich um Nachwuchsnominierungen (bitte bei der Nominierung angeben).
Gewählt werden können Forschende, die
- an einer deutschen akademischen Institution (im Sinne einer bei der DFG antragsberechtigten Institution) tätig sind,
- sich sich mit den Zielen und Aufgaben von Text+ identifizieren,
- nicht Teil des geförderten Projekts sind,
- deren Forschungsinteressen einem der Bereiche von Text+ zugeordnet werden können.
Der Wahlausschuss wird im Vorfeld der Wahl mit den Nominierten Kontakt aufnehmen und die Bereitschaft zur Kandidatur erfragen.
Die Ansprechpersonen der Organisationen, Institutionen und Einrichtungen, die wahlberechtigt sind, erhalten zum Wahltermin die Zugangsdaten zum Wahlsystem.
Weitere Informationen finden Sie unter https://text-plus.org/ueber-uns/governance/komiteebesetzung/
Rückfragen richten Sie gerne jederzeit über office@text-plus.org an den Wahlausschuss.
Stellenanzeige: Elternzeitvertretung für die wissenschaftliche Mitarbeit als Redaktionsleitung (m/w/d) der Zeitschrift für digitale Geisteswissenschaften
An der Herzog August Bibliothek ist zum nächstmöglichen Zeitpunkt eine bis zum 30.09.2025 befristete Teilzeitstelle als Elternzeitvertretung für die
wissenschaftliche Mitarbeit als Redaktionsleitung (m/w/d) der Zeitschrift für digitale Geisteswissenschaften (bis zu 0,75 Entgeltgruppe 13 TV-L)
zu besetzen. Eine Beschäftigung ist mit bis zu 30 Wochenstunden möglich.
Den Link zur Stellenanzeige finden Sie hier.
Die Zeitschrift für digitale Geisteswissenschaften ist ein innovatives Forschungsperiodikum, das sich Themen an der Schnittstelle von geisteswissenschaftlicher und digitaler Forschung widmet. Sie wird gemeinsam herausgegeben vom Forschungsverbund Marbach Weimar Wolfenbüttel und dem Verband Digital Humanities im deutschsprachigen Raum e.V. Die Tagesredaktion unter Leitung der Redaktionsleitung hat ihren Sitz und Arbeitsort an der Herzog August Bibliothek in Wolfenbüttel.
Ihre Aufgaben:
In Zusammenarbeit mit der Fachredaktion, der technischen Redaktion, der Textredaktion und einer bibliothekarischen Fachkraft:
- Redaktionelle Leitung des E-Journals „Zeitschrift für digitale Geisteswissenschaften“ (ZfdG, https://zfdg.de)
- Planung, Annahme und redaktionelle Bearbeitung (inkl. Tagging) und Layouten von Artikeln
- Betreuung von Autorinnen und Autoren
- Weiterentwicklung, Moderation und Koordination der Qualitätssicherungs- und Review-Verfahren für die Zeitschrift
- Akquise neuer Artikel und Sonderbände
- Weiterentwicklung der vorhandenen Publikationsinfrastruktur
- Kontaktpflege zu Interessensvertretungen der Digital Humanities und einschlägiger geisteswissenschaftlicher Fachgesellschaften sowie Vernetzung mit anderen E-Journals
- Projektleitung und Umsetzung des Projekts „Nachhaltig innovativ: Diamond Open Access für die digitalen Geisteswissenschaften“ im Rahmen des Förderprogramms NiedersachsenOPEN (Laufzeit: 01.06.2024 bis 31.12.2025)
- Koordination und Umsetzung der Maßnahmen zum 10. Jubiläum der ZfdG (in Zusammenarbeit mit der Stabsstelle Presse- und Öffentlichkeitsarbeit/Kulturprogramm der HAB), insbesondere Umsetzung der Social-Media-Strategie, Vertretung der Zeitschrift auf Fachkonferenzen, Organisation von Jubiläumsveranstaltungen
- Betreuung von Redaktionspraktikantinnen und -praktikanten
- Erstellung eines Workshop-/Vermittlungskonzept für Publikationskompetenzen an Studierende der Digital Humanities
Voraussetzungen:
- Abgeschlossenes geisteswissenschaftliches oder informationswissenschaftliches Studium (Master-Abschluss oder vergleichbar)
- Nachgewiesene Kenntnisse im Bereich der Digital Humanities
- Redaktionserfahrung mit wissenschaftlichen Publikationen
- Nachgewiesene und einschlägige Erfahrungen als Redakteur/in im Bereich wissenschaftlicher Online-Publikationen und -Portale. Vertrautheit mit modernen Publikationsmethoden und -modellen (Single-Source-Publishing, Diamond Open Access etc.)
- Solide Kenntnisse in XML/TEI
- Gute Kommunikations-, Organisations- und Teamfähigkeit
- Gute Englischkenntnisse
Als familiengerechte Bibliothek, Forschungs- und Studienstätte bietet die HAB ein abwechslungsreiches Aufgabenspektrum, flexible Arbeitszeiten sowie regelmäßige Fort- und Weiterbildungsmöglichkeiten. Mobile Arbeit ist möglich. Als Tarifbeschäftigte/r erhalten Sie eine Jahressonderzahlung im Rahmen des TV-L sowie die Teilnahme an der zusätzlichen Altersversorgung im öffentlichen Dienst über die VBL. Es erwartet Sie ein engagiertes und aufgeschlossenes Team.
Die HAB strebt an, Unterrepräsentanzen im Sinne des NGG in allen Bereichen und Positionen abzubauen. Die Gleichstellung von Frauen und Männern wird gefördert. Schwerbehinderte Bewerberinnen und Bewerber werden bei gleicher Eignung und Befähigung bevorzugt behandelt. Ein Nachweis ist beizufügen.
Bewerbungen mit aussagefähigen Unterlagen werden bis zum 15.10.2024 mit dem Kennwort „ZfdG Redaktion“ möglichst per E-Mail (PDF-Dokument) erbeten an die
Herzog August Bibliothek Wolfenbüttel
Verwaltung Lessingplatz 1
38304 Wolfenbüttel
E-Mail: verwaltung@hab.de
Interessentinnen und Interessenten können sich bei Frau Jansky telefonisch unter (05331) 808-214 oder per E-Mail unter jansky@hab.de über das Arbeitsgebiet informieren.
Bewerbungsunterlagen werden grundsätzlich nicht zurückgesandt, sondern datenschutzgerecht vernichtet. Sollte eine Rücksendung gewünscht sein, bitten wir um Beilage eines adressierten und ausreichend frankierten Rückumschlags.
Hinweis zum Datenschutz: Mit der Einreichung Ihrer Bewerbung stimmen Sie der Verarbeitung Ihrer personenbezogenen Daten im Rahmen und zur Durchführung des Bewerbungsverfahrens zu. Diese Einwilligung kann jederzeit ohne Angabe von Gründen gegenüber o.g. Stelle(n) schriftlich oder elektronisch widerrufen werden. Bitte beachten Sie, dass ein Widerruf der Einwilligung u. U. dazu führt, dass die Bewerbung im laufenden Verfahren nicht mehr berücksichtigt werden kann.
Umfrage zu Praktiken, Standards und Bedarfen im Bereich Datenqualität von NFDI4Memory
Die Task Area “Data Quality” des Konsortiums NFDI4Memory in der Nationalen Forschungsdateninfrastruktur (NFDI) möchte einen Überblick gewinnen, wie die Community der historisch arbeitenden Fächer die Qualität ihrer Daten gewährleistet, welche Standards sie hierbei verwendet und welche Bedarfe sie hat.
Dazu haben wir eine Umfrage entworfen. Wir laden Sie herzlich ein, daran teilzunehmen:
https://www.herder-institut.de/limesurvey/index.php/899418?newtest=Y&lang=de
Diese Umfrage richtet sich daher an alle, die in den historisch arbeitenden Fächern Daten erzeugen, bearbeiten, speichern und nachnutzen. Unter Forschungsdaten verstehen wir in NFDI4Memory zum einen alle Daten (und auch Metadaten), die im Rahmen von Forschungsvorhaben entstehen bzw. verwendet werden und zum anderen (Meta-)Daten, die in Infrastruktureinrichtungen (Archive, Bibliotheken, Museen) erstellt, gesammelt und vorgehalten werden.
Die Beantwortung des Fragebogens dauert ca. 15 Minuten.
Die Umfrage läuft bis zum 15. Oktober 2024.
Virtuelles DH-Kolloquium an der BBAW, 30.09.2024: „Automatische Texterkennung für die (digitalen) Geisteswissenschaften – OCR4all als Open-Source-Ansatz“
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 30. September 2024, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Christian Reul (Universität Würzburg)
über
Automatische Texterkennung für die (digitalen) Geisteswissenschaften – OCR4all als Open-Source-Ansatz
***
Ein zentraler Aspekt der Arbeit von geistes- und kulturwissenschaftlich Forschenden ist die Auseinandersetzung mit historischen Quellen in Form von gedruckten und handschriftlichen Textzeugen. Diese liegen häufig lediglich als Scans vor, aus denen zunächst maschinenverarbeitbarer Volltext extrahiert werden muss, wozu Methoden der automatischen Texterkennung zum Einsatz kommen. Dabei stellen gerade sehr alte Drucke und Handschriften aus verschiedensten Gründen häufig noch eine große Herausforderung dar. Das am Zentrum für Philologie und Digitalität (ZPD) der Universität Würzburg entwickelte, frei verfügbare Open-Source-Tool OCR4all hat zum Ziel, auch technisch weniger versierten Nutzenden die Möglichkeit zu geben, anspruchsvolle Drucke und Handschriften selbstständig und in höchster Qualität zu erschließen. OCR4all fasst den gesamten Texterkennungsworkflow und alle dafür benötigten Tools in einer einzigen Anwendung zusammen, die über eine komfortable grafische Nutzeroberfläche bedient werden kann.
Der Vortrag erläutert zunächst die Grundlagen der automatischen Texterkennung und stellt OCR4all und dessen Funktionsweise vor. Weiterhin wird die Anwendbarkeit und Performanz auf unterschiedlichem Material demonstriert und ein Überblick über aktuelle Arbeiten sowie ein Ausblick auf zukünftige Entwicklungen gegeben.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
Konferenzbericht DH2024 „Reinvention & Responsibility“, Washington DC
Dieser Beitrag ist im Rahmen eines Reisekostenstipendiums für die DH2024 entstanden. Ich möchte mich an dieser Stelle herzlich beim Verband Digital Humanities im deutschsprachigen Raum (DHd) dafür bedanken, mir die Teilnahme an der Konferenz zu ermöglichen. Auch möchte ich die tolle Arbeit der Organisator:innen hervorheben und mich dafür bedanken.
Die DH2024, organisiert von der Alliance of Digital Humanities Organizations (ADHO), fand vom 6. bis 9. August 2024 an der George Mason University in Arlington, Virginia, statt. Unter dem Thema „Neuerfindung & Verantwortung“ bot die Tagung Digital Humanists aus aller Welt eine Plattform, um ihre Forschungsergebnisse und aktuelle Entwicklungen im Feld zu präsentieren.
Workshops und EröffnungDie Konferenz begann am Montag und Dienstag mit praxisorientierten Workshops, die sich auf die Anwendung von Methoden, Software und Werkzeugen konzentrierten. Der offizielle Konferenzbeginn folgte am Dienstagabend mit der Eröffnungszeremonie, einem Empfang und einer Keynote von Susan Brown, der in diesem Rahmen auch der „Roberto Busa Preis“ verliehen wurde. In ihrer Keynote gab Susan Brown einen Einblick in ihre Arbeit zur Verknüpfung von Forschungsdaten (Linked Open Data). Den Mittwoch eröffnete die Datenjournalistin Linda Ngari mit einer weiteren Keynote. In dieser berichtete sie aus ihrer Erfahrung als Journalistin, ein interprofessioneller Ausflug, der auch für die Digitalen Geisteswissenschaften relevante Erkenntnisse mit sich brachte, wie beispielsweise den eindringlichen Appell die Integrität von Forschungsdaten – insbesondere wenn diese durch Dritte erzeugt werden – kritisch zu hinterfragen.
Einige Beobachtungen aus den PanelsIm Anschluss starteten die thematischen Panels. Bei fast 90 parallel laufenden Panels, die sich meist aus mehreren kürzeren Vorträgen zusammensetzten, bleibt mir nur die Möglichkeit, einige aggregierte (und vermutlich subjektive) Eindrücke zu schildern.
Eine Reihe von Vorträgen beschäftigte sich mit der Langzeitverfügbarkeit und Nachnutzbarkeit von Forschungsdaten, Publikationsplattformen und digitalen Editionen. Besonders im gut besuchten Panel „Sustainability of Digital Publishing Platforms“ wurde diskutiert, welche Verbesserungen bereits erzielt wurden und was in Zukunft noch optimiert werden könnte. Statt rein technischer Lösungen standen vor allem soziale und finanzielle Herausforderungen im Fokus, insbesondere die Vermittlung von Anforderungen zwischen verschiedenen Disziplinen und Funktionsträgern. Ein zentrales Fazit war, dass qualifiziertes, langfristig beschäftigtes Personal entscheidend zur Nachhaltigkeit von Publikationen beitragen kann. Technisch gesehen wurde der Trend sichtbar, etablierte Standards und Anwendungen zu bevorzugen und die Stabilität gegenüber der Innovationsfreude zu priorisieren.
Ein weiterer wiederkehrender Themenkomplex drehte sich um Large Language Models (LLMs). Stabile, nachvollziehbare und reproduzierbare Ergebnisse konnten vor allem die Ansätze erzielen, die auf bewährte Komponenten von Sprachmodellen zurückgreifen, wie z. B. die Verwendung von LLM-Embeddings. Auch die Nutzung von LLMs als „eigenständige Agenten“ zur Automatisierung von Arbeitsschritten wurde thematisiert, wobei viele dieser Ansätze noch im Planungsstadium stecken, und konkrete Ergebnisse noch nicht präsentiert werden konnten. Zudem waren LLMs selbst Gegenstand der Forschung, etwa in einer qualitativen Analyse zu rassistischen Biases in Sprachmodellen.
Ein für mich besonders interessantes Panel stellte neue Ansätze in der historischen Reiseforschung vor. Diese Ansätze lösen sich von der konventionellen Geolokalisierung und ermöglichen es, Quellen zu berücksichtigen, die keine eindeutigen geographischen Verortungen zulassen. In der Analyse und Visualisierung werden diese Informationen in Form von Netzwerkgraphen oder gewichteten Punkten dargestellt. Da die Forschung sich noch in der Entwicklung befindet, bin ich gespannt, wie sich diese Ansätze weiter entwickeln.
Neben den zahlreichen Vorträgen gab es zwei Poster-Sessions. Am Freitagnachmittag präsentierte ich das Poster unseres Projektteams und konnte dabei interessante Gespräche mit den Teilnehmer:innen der Konferenz führen. Gleich im Anschluss daran endete die DH2024 mit der Abschlusszeremonie. Die abschließende Keynote hielt Shannon Mattern, die die Verschränkung sozialer und technischer Aspekte in der Medienkommunikation thematisierte. Besonders inspirierend fand ich ihren Gedanken, dass Kommunikationsmedien nicht voraussetzungslos existieren, und man die eigene Nutzung kritisch dahingehend prüfen sollte, ob sie nicht möglicherweise die Grundlagen untergräbt, auf denen man aufbaut.
FazitDie DH2024 in Arlington war eine spannende und bereichernde Konferenz. Der Austausch mit internationalen Kolleg:innen und die Vielfalt der Themen haben mir wertvolle neue Impulse für meine eigene Arbeit gegeben und ich freue mich darauf, an zukünftigen Konferenzen teilzunehmen.
Einladung zum DHd-Community Forum am 11.10.2024
Liebe Mitglieder des DHd-Verbandes und Interessierte,
für unsere interdisziplinäre Community ist ein offener Austausch von großer Bedeutung. Während die jährliche Mitgliederversammlung bereits eine wichtige Rolle für unsere communityinterne Verständigung übernimmt, unterstützen wir als Vorstand weitere partizipative Angebote. Alle Mitglieder und Interessierte sind herzlich eingeladen, sich an den Diskussionen zu beteiligen sowie Themenvorschläge (info@dig-hum.de) einzureichen.
Das nächste virtuelle Community Forum findet am Freitag, dem 11. Oktober 2024 von 14–15 Uhr statt.
Gegenstand des Community Forums sind die DHd-Förderprogramme für Early Career Researcher (DHd-Reisestipendien, Mentoring). Das Community Forum richtet sich daher auch explizit an Studierende aus DH-Studiengängen. Insbesondere soll die Einrichtung einer Taskforce „Dissertationspreis” diskutiert werden, dazu soll es die Möglichkeit für einen Austausch über Erwartungshorizonte und Herausforderungen geben. Weitere Themen können wie immer zu Beginn des Community Forums vorgeschlagen werden.
Für das Community Forum werden wir das Videokonferenztool BigBlueButton nutzen. Wir möchten Sie bitten, sich mit vollständigem Namen anzumelden.
https://webroom.hrz.tu-chemnitz.de/gl/rab-rg7-psq-qcn
Wir freuen uns auf den Austausch mit Ihnen!
Mit freundlichen Grüßen
Rabea Kleymann (als Koordinatorin des Community Forums)
Stellenausschreibung Softwareentwickler/in (m/w/d) an der Niedersächsischen Akademie der Wissenschaften zu Göttingen
An der Niedersächsischen Akademie der Wissenschaften zu Göttingen
ist zum 1. Januar 2025 in dem durch die Germania Sacra koordinierten Vorhaben „Forschungsdateninfrastruktur Historische Quellen (HisQu)“
die Stelle einer wissenschaftlichen Mitarbeiterin/eines wissenschaftlichen Mitarbeiters (w/m/d)
im Umfang 100 % (TV-L E13) zu besetzen. Die Stelle ist befristet bis zum 31. Dezember 2027. Sie ist teilzeitgeeignet.
Das im Rahmen des e-Research-Programms von der DFG zunächst für 3 Jahre geförderte Forschungsprojekt HisQu ist ein kollaboratives Vorhaben zur Entwicklung einer digitalen Infrastruktur für historische Quellen. Kern der Infrastruktur ist ein ontologiebasierter Wissensgraph. Als Datenspeicher wird eine domänenspezifische Wikibase-Instanz evaluiert. Für die Erschließung und Erweiterung des Wissensgraphen werden im Rahmen des Projekts flexibel anpassbare Nutzerinterfaces entwickelt. In Zusammenarbeit mit renommierten Partnerinstitutionen wird dafür eine Plattform aufgebaut, die es ermöglicht, historische Forschungsprozesse digital gestützt, nachvollziehbar und reproduzierbar zu gestalten.
Ihre Aufgaben:
- Mitarbeit an der Entwicklung einer Ontologie und dem Datenmodell in Zusammenarbeit mit den Projektbeteiligten
- Entwicklung eines benutzerfreundlichen Interfaces für den HisQu-Wissensgraphen
- Zusammenarbeit mit Entwicklerteams und Fachwissenschaftlern
- Dokumentation der Entwicklungsprozesse und Mitarbeit an den Publikationen des Forschungsprojekts
- Koordination von studentischen Assistenzen
Ihr Profil:
- Ein abgeschlossenes Masterstudium in Informatik, Interface Design, Digital Humanities oder einem verwandten Bereich
- Sehr gute Kenntnisse von Webtechnologien sowie in der Webentwicklung
- Idealerweise Kenntnisse von Wikibase sowie Standards zur Wissensmodellierung (RDF)
- Selbstständige und strukturierte Arbeitsweise sowie Teamfähigkeit und die Bereitschaft, in einem interdisziplinären Umfeld zu arbeiten
- Interesse an geschichtswissenschaftlichen Fragestellungen und der Anwendung moderner Technologien in der historischen Forschung
Wir bieten:
- Eine verantwortungsvolle und vielseitige Tätigkeit in einem innovativen Forschungsprojekt
- Die Möglichkeit, an der Schnittstelle von Informatik und Geschichtswissenschaften zu arbeiten
- Ein internationales Arbeitsumfeld mit engen Kontakten zu führenden Forschungsinstitutionen
Informationen zum Vorhaben unter: https://adw-goe.de/germania-sacra/hisqu. Ansprechpartnerin bei Fragen: Bärbel Kröger, baerbel.kroeger@adwgoe.de, 0551 39-21558.
Die Akademie strebt in den Bereichen, in denen Frauen unterrepräsentiert sind, eine Erhöhung des Frauenanteils an und fordert daher qualifizierte Frauen ausdrücklich zur Bewerbung auf. Sie versteht sich zudem als familienfreundlich und fördert die Vereinbarkeit von Wissenschaft/Beruf und Familie. Schwerbehinderte Menschen werden bei entsprechender Eignung besonders berücksichtigt.
Eine Bewerbung, in der Sie bitte nach Möglichkeit auch angeben, ob Sie eine Vollzeit- oder Teilzeitbeschäftigung anstreben, senden Sie bitte bis zum 16. Oktober 2024 als eine PDF-Datei (max. 5 MB) per E-Mail an: adw.bewerb@adwgoe.de, an die Niedersächsische Akademie der Wissenschaften zu Göttingen, Theaterstraße 7, 37073 Göttingen.
Reise- und Bewerbungskosten können nicht erstattet werden. Wir weisen darauf hin, dass die Einreichung der Bewerbung eine datenschutzrechtliche Einwilligung in die Verarbeitung Ihrer Bewerbungsdaten durch uns darstellt. Näheres zur Rechtsgrundlage und Datenverwendung: https://adw‐goe.de/ueber‐uns/datenschutzerklaerung/.
TextGrid Repository erneut mit dem CoreTrustSeal ausgezeichnet!
Das TextGrid Repository ist ein digitales Langzeitarchiv für geisteswissenschaftliche Forschungsdaten, das einen umfangreichen, durchsuch- und nachnutzbaren Bestand an Texten und Bildern liefert. Es ist an den Grundsätzen von Open Access und den FAIR-Prinzipien orientiert und fokussiert sich auf Texte in XML TEI, um vielfältige Szenarien der Nachnutzung zu unterstützen. Für Forschende bietet das TextGrid Repository eine nachhaltige, dauerhafte und sichere Möglichkeit zur zitierfähigen Publikation ihrer Forschungsdaten und zur verständlichen Beschreibung derselben durch erforderliche Metadaten. Mehr Informationen zum Thema Nachhaltigkeit, FAIR und Open Access befinden sich im Mission Statement des TextGrid Repository.
Der Bestand basiert auf dem Erwerb der Digitalen Bibliothek und wurde durch zahlreiche Editions- und Korpusprojekte erweitert. Dadurch befinden sich nun auch Manuskripte (Bilder) und Transkriptionen (XML/TEI-kodierte Textdaten) im TextGrid Repository, z.B. die Bibliothek der Neologie oder auch das Projekt zur deutsch-französischen Reisekorrespondenz ARCHITRAVE. Neue Texte im TextGrid Repository sind die Korpora der European Text Collection (ELTec) und das Corpus of Novels of the Spanisch Silver Age (CoNSSA)
Bereits im Jahr 2020 wurde das TextGrid Repository erstmalig mit dem CoreTrustSeal zertifiziert, das alle drei Jahre erneuert werden muss. Nun wurde das TextGrid Repository erneut mit dem CoreTrustSeal ausgezeichnet!
Das CoreTrustSeal (CTS) ist eine internationale, gemeinnützige Organisation mit dem Ziel, vertrauenswürdige Dateninfrastrukturen zu fördern. Sie zertifiziert Repositorien auf Grundlage des Anforderungskatalogs der Core Trustworthy Data Repositories Requirements. Dieser fragt Kernkompetenzen von vertrauenswürdigen Repositorien ab. Nachdem eine Zertifizierung beantragt wurde, wird der Antrag von einer Reihe internationaler Prüferinnen und Prüfer bearbeitet. Die CoreTrustSeal-Zertifizierung gehört zu den bekanntesten und international anerkannten Zertifizierungen.
Dadurch befindet sich das TextGrid Repository weiterhin in der Riege international renommierter und CTS-zertifizierter Repositorien. Das Zertifikat ist bis 2027 gültig und soll weiterhin regelmäßig erneuert werden.
Weitere inhaltliche Informationen zum DARIAH-DE Repository finden Sie im Dokumentationsbereich des TextGrid-Website, technische Informationen auf der Dokumentationsseite des Repository-Servers.
Call for Posters: Methodenmesse auf der IDS-Jahrestagung 2025 in Mannheim
Vom 11.-13. März 2025 findet die Jahrestagung 2025 des Leibniz-Instituts für Deutsche Sprache in Mannheim unter dem Rahmenthema „Deutsch im Wandel“ statt.
Bestandteil der Tagung wird am Mittwoch, 12. März 2025, eine Projekt- und Methodenmesse zu diesem Thema sein. Wir rufen auf zur Einreichung von Beiträgen, die sich mit methodischen Ansätzen und Perspektiven zur Erforschung von Sprachwandel und seinen Determinanten auseinandersetzen. Der Fokus liegt auf Ressourcen, Methoden und Werkzeugen, die am besten anhand kurzer Anwendungsstudien präsentiert werden. Dabei begrüßen wir insbesondere Beiträge, die sich mit der deutschen Sprache beschäftigen bzw. auf das Deutsche anwendbare Methoden oder Tools vorstellen.
Insbesondere freuen wir uns über:
- Beiträge, die für andere nutzbare schriftliche oder mündliche Korpora vorstellen, die sich zur Erforschung von Sprachwandel eignen,
- Beiträge, die empirische Daten anderen Typs (z.B. Eye Tracking oder Sprachumfragedaten) vorstellen, die sich zur Erforschung von Sprachwandel eignen,
- Beiträge zu Werkzeugen, Tools oder Plattformen für die Untersuchung von Sprachwandel,
- Beiträge, die sich mit praktischen Herausforderungen der Untersuchung von Sprachwandel beschäftigen, z.B. Korpusaufbau oder Datenaufbereitung für die statistische Analyse von Sprachwandeldaten,
- Beiträge zur Visualisierung und zu anderen Methoden der Vermittlung von Ergebnissen der Sprachwandelforschung,
- Beiträge, die sich auf neuartige Methoden der Operationalisierung/Messung von Sprachwandel (z.B. mit Hilfe von Large Language Models) fokussieren.
Die Beiträge werden in Form eines Posters und ggf. einer Softwaredemonstration präsentiert. Auf der Tagung wird jeder Beitrag in einem einminütigen Schlaglicht dem Publikum vorgestellt, anschließend gibt es die Gelegenheit, die Inhalte im Rahmen einer ca. eineinhalbstündigen Postersession zu demonstrieren und Fragen zu beantworten. Ausgearbeitete Beiträge sollen im Anschluss an die Tagung bei IDSopen digital nach dem Open-Access-Prinzip publiziert werden.
Wenn Sie einen Beitrag zur Methodenmesse beisteuern möchten, bitten wir um ein nicht anonymisiertes Abstract auf Deutsch (ca. 500 Wörter exkl. Literaturangaben; in einem editierbaren Format) bis zum 30. September 2024 an die Adresse methodenmesse2025@ids-mannheim.de. Über die Annahme der Beiträge entscheidet das Organisationsteam bis zum 30. November 2024.
Organisationsteam: Annelen Brunner, Gabriele Diewald, Sandra Hansen, Kristin Kopf, Angelika Wöllstein
Wissenschaftliche/n Mitarbeiter/in (m/w/d)
Die Berlin-Brandenburgische Akademie der Wissenschaften (BBAW) ist eine Vereinigung von Wissenschaftlerinnen und Wissenschaftlern mit einer über 300-jährigen Geschichte, die den Dialog zwischen Wissenschaft und Gesellschaft fördert. Ihr wissenschaftliches Profil ist vor allem geprägt durch geistes- und kulturwissenschaftliche Grundlagenforschung, interdisziplinäre Gesellschafts- und Politikberatung auf verschiedenen Feldern und die Kommunikation von Wissenschaft in die Öffentlichkeit.
Die Akademie startete 2024 das interakademische Akademienvorhaben „Historische Fremdsprachenlehrwerke digital. Sprachgeschichte, Sprachvorstellungen und Alltagskommunikation im Kontext der Mehrsprachigkeit im Europa der Frühen Neuzeit“ unter Leitung von Prof. Dr. Horst Simon (Freie Universität Berlin), Prof. Dr. Natalia Filatkina (Universität Hamburg) und Prof. Dr. Andrea Rapp (Technische Universität Darmstadt). Dessen Ziel ist die Volltexterschließung, korpuslinguistische Aufbereitung, Annotation, digitale Vernetzung sowie die sprach-, kultur- und wissenshistorische Auswertung von mehrsprachigen Fremdsprachenlehrwerken aus der Frühen Neuzeit. Im Rahmen des Vorhabens wird das gesamte überlieferte Material, in dem das Deutsche eine der Sprachen ist, nach einem gestuften Konzept volltexterschlossen, nachhaltig aufbereitet und für weitere Analysen bereitgestellt. Damit wird es zum ersten Mal möglich sein, die historischen Wurzeln der heutigen Mehrsprachigkeit in Europa aus der Perspektive alltagssprachlicher Praxis des Fremdsprachenerwerbs und der Fremdsprachen- und Wissensvermittlung in der Frühen Neuzeit zu beantworten.
Die Akademie sucht für dieses Akademienvorhaben zum frühestmöglichen Zeitpunkt
eine/n wissenschaftliche/n Mitarbeiter/in (m/w/d)mit Gelegenheit zur Promotion im Umfang von 65 % der vollen tariflichen Arbeitszeit. Die Stelle ist vorerst befristet auf 24 Monate (eine Verlängerung wird angestrebt)
Ihre Aufgaben:
- Wissenschaftliche Mitarbeit bei der Erstellung, Annotation und Analyse eines digitalen Korpus frühneuzeitlicher Fremdsprachenlehrwerke
- Forschung im Bereich von Historischer Grammatik/Pragmatik/Soziolinguistik anhand des Korpusmaterials bzw. Forschung im Bereich Linguistik multilingualer Korpora
Ihr Profil:
- Erfolgreich abgeschlossenes Hochschulstudium in einem projektrelevanten philologischen Fach (Germanistik, Romanistik, Slawistik und/oder Allgemeine Sprachwissenschaft o. ä.)
- Sehr gute Kenntnisse im Bereich der Historischen Sprachwissenschaft und / oder Korpuslinguistik
- Sehr gute Kenntnisse in mehreren der relevanten Korpussprachen (einschließlich historischer Sprachstufen mindestens einer), vor allem Deutsch, Französisch, Italienisch, Spanisch, auch Latein, Englisch, Niederländisch, Polnisch, Tschechisch usw.
- Interesse an wissens- und kulturhistorischen Fragestellungen
- Es wird erwartet, dass eine sprachwissenschaftliche Promotion im Themenbereich des Projekts erarbeitet wird.
- Erfahrung mit digitalen Arbeitsumgebungen
- Sehr gute Deutsch- und Englischkenntnisse
- Aufgeschlossenheit gegenüber neuen Anforderungen und Bereitschaft, sich in neue Fragestellungen und Methoden einzuarbeiten
- Ausgeprägte Kommunikations- und Teamfähigkeit
Was wir bieten:
- Eine anspruchsvolle und abwechslungsreiche Tätigkeit in einem engagierten Team an einer lebendigen Forschungseinrichtung
- Betriebliche Altersvorsorge und vermögenswirksame Leistungen
- Zuschuss zum VBB-Firmenticket
- 30 Tage Urlaub bei einer Vollzeittätigkeit, zusätzlich 24.12. und 31.12. freigestellt
- Attraktive Möglichkeiten zur wissenschaftlichen Weiterentwicklung im aktiven Digital-Humanities-Umfeld der BBAW
- Familienfreundliche Arbeitsbedingungen an einem attraktiven Arbeitsplatz in Berlin-Mitte
Die Vergütung erfolgt nach der Entgeltgruppe E 13 TV-L Berlin. Der Dienstort ist Berlin.
Die Berlin-Brandenburgische Akademie der Wissenschaften ist bestrebt, den Anteil von Frauen in Bereichen, in denen sie unterrepräsentiert sind, nach Maßgabe des Landesgleichstellungsgesetzes und des Frauenförderplanes zu erhöhen, daher sind Bewerbungen von Frauen ausdrücklich erwünscht. Bewerbungen von Frauen werden bei gleichwertiger Qualifikation bevorzugt berücksichtigt. Bewerbungen von Personen mit Migrationshintergrund sind ausdrücklich erwünscht; Bewerbungen von schwerbehinderten Personen werden bei gleicher Eignung vorrangig berücksichtigt.
Als Ansprechpartnerin steht Ihnen die Leiterin der Arbeitsstelle, Dr. Josephine Klingebeil-Schieke, zur Verfügung (josephine.klingebeil-schieke@bbaw.de).
Ihre aussagekräftigen Bewerbungsunterlagen richten Sie bitte möglichst in einer PDF-Datei (max. 5 MB) unter der Kennziffer AV 06 2024 bis zum 26.09.2024 an die:
Berlin-Brandenburgische Akademie der Wissenschaften
Referat Personal und Recht
Ines Hanke
Jägerstraße 22/23, 10117 Berlin
Bitte laden Sie Ihre Bewerbungsmappe unter folgendem Link hoch:
https://nubes.bbaw.de/s/RbiqBJoGJaZk8R3
Bitte beachten Sie, dass wir nach Ende der Bewerbungsfrist zu Ihnen Kontakt aufnehmen werden und Sie nach dem Upload der Bewerbungsunterlagen zunächst keine separate Bestätigung erhalten.
Die Auswahlgespräche finden voraussichtlich in der 42. Kalenderwoche in Berlin statt.
Edirom Summer School 2024
Das Zentrum Musik – Edition – Medien (ZenMEM) und der Virtuelle Forschungsverbund Edirom (ViFE) laden sehr herzlich ein zur diesjährigen 15. Edirom Summer School vom 23. bis 27. September im Heinz-Nixdorf-Institut der Universität Paderborn. Die Registrierung ist offen bis 18. September 2024.
Keynote
Zum Auftakt spricht Dr. Tessa Gengnagel am Mo. 23. Sept. ab 18:15 Uhr im Foyer des HNI (Fürstenallee 11) über
„Walzerkrieg und Maschinengott: Zur Edition multimedialer Werkkomplexe am Beispiel von Film und Musik“
Zur öffentlichen Keynote sind Sie auch ohne vorherige Anmeldung sehr herzlich eingeladen. Die Keynote wird digital gestreamt, der Link wird noch bekanntgegeben.
Programm
Das umfangreiche Kursprogramm (https://ess.uni-paderborn.de/2024/programm.html) rund um Digitale Edition, digitales Arbeiten in den Kultur- und Geisteswissenschaften, Textkodierung und Musikkodierung richtet sich an Interessierte aller Fächer.
Anmeldung
Die Anmeldung zur ESS (https://ess.upb.de/2024/registrierung.html) ist noch bis zum 18. September möglich. Warten Sie aber nicht zu lange, denn wir können in diesem Jahr aus Kapazitätsgründen auch bei hoher Nachfrage keine Zusatzkurse anbieten! Für Studierende der UPB, die die ESS als Lehrveranstaltung (Blockseminar) besuchen, sind die Kurse kostenlos.
Poster-Session
Sie haben ein Projekt, eine Idee oder möchten einfach zeigen woran Sie arbeiten? Dann nichts wie raus aus dem Elfenbeinturm! Stellen Sie einfach ein Poster zusammen und bringen Sie es mit zur ESS. Wir freuen uns über alle Poster-Vorschläge, die uns (formlos) über ess@edirom.de erreichen.
Weitere Infos unter https://ess.upb.de/2024/programm.html
Für Rückfragen ist das Orga-Team der Edirom-Summer-School unter ess(at)edirom(dot)de zu erreichen.
Bleibt alles anders: 10 Jahre correspSearch
Seit 2014 sammelt correspSearch die Metadaten von edierten Briefen und stellt sie zur projektübergreifenden Recherche bereit. Pünktlich zum runden Geburtstag gibt es jetzt neue Features: Visualisierungen, Volltextsuche und einen SPARQL-Endpoint. Über 270.000 edierte Briefe sind recherchierbar. Grund genug, nicht nur die neuen Funktionen vorzustellen, sondern auch zurück zu blicken und zu schauen, was noch kommt.
Von Stefan Dumont, Sascha Grabsch, Jonas Müller-Laackman, Ruth Sander und Steven Sobkowski
Blick zurück
Vor zehn Jahren, genauer gesagt am 1. September 2014, ging correspSearch mit einer E-Mail an die TEI-Liste und einem DHd-Blogpost offiziell online. Die Initiative zum Webservice war im Februar 2014 im Workshop „Briefeditionen um 1800: Schnittstellen finden und vernetzen“ entstanden, der von Anne Baillot und Markus Schnöpf an der BBAW organisiert worden war. Dort stellte Peter Stadler die Überlegungen zum geplanten TEI-Element correspDesc vor und äußerte in diesem Rahmen auch die Idee, über ein Austauschformat Korrespondenzmetadaten aus Briefeditionen bereitzustellen und editionsübergreifend zu aggregieren (Stadler 2014).
Screenshot der Suchoberfläche im Prototypen von correspSearch, ca. 2015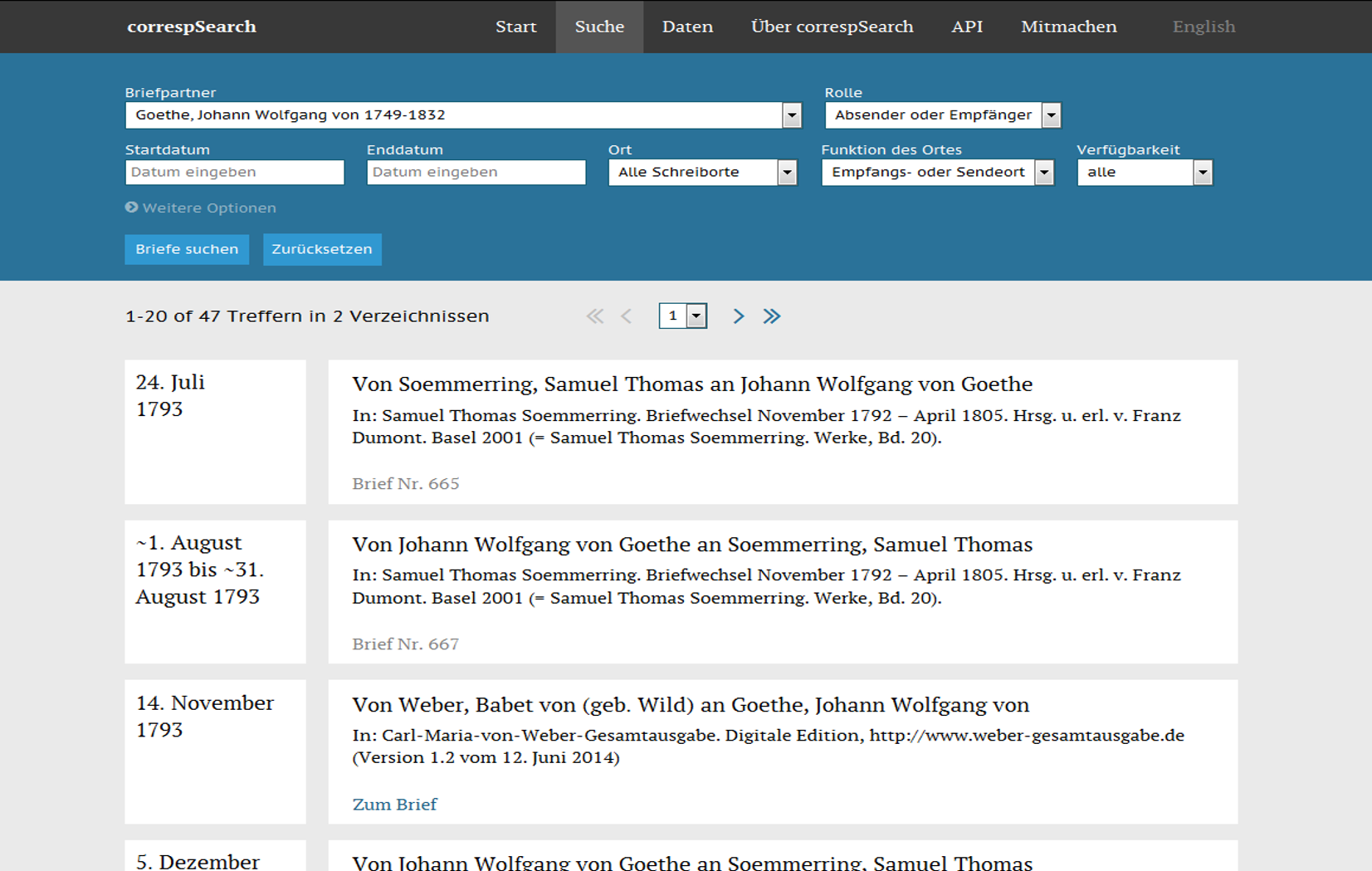{kind=link}
Im Nachgang zum Workshop wurde an der BBAW von Stefan Dumont der Prototyp eines Webservices entwickelt, der Dateien aggregieren und basal schon recherchierbar machen konnte: correspSearch (Dumont 2018; 2023). Gleichzeitig wurde von einer Taskforce der TEI Correspondence SIG die Modellierung von correspDesc abgeschlossen (Stadler, Illetschko und Seifert 2016). Mit dem Eingang von correspDesc in die TEI-Richtlinien (Version 2.8.0) im Frühjahr 2015 konnte auch das Correspondence Metadata Interchange Format (CMIF), das ebenfalls im Rahmen der TEI Correspondence SIG entwickelt wurde, in einer ersten Version finalisiert werden. Das CMIF setzt auf ein sehr reduziertes und restriktives Set an Elementen (und damit Informationen). Charakteristisch ist die konsequente Nutzung von URIs aus Normdateien wie der Gemeinsamen Normdatei (GND) für Personen und GeoNames für Orte. Dadurch können diese Entitäten projektübergreifend eindeutig identifiziert und gesucht werden.
Von Beginn an war correspSearch auf die Datenbereitstellung seitens der Editionsvorhaben, Forschungsprojekte und Institutionen angewiesen. Datenbeiträger der ersten Stunde waren z.B. die Weber-Gesamtausgabe und Briefe und Texte aus dem intellektuellen Berlin um 1800. In den folgenden Jahren wuchs der Datenbestand langsam, aber stetig an. Im Sommer 2016 konnten schon über 17.000 edierte Briefe nachgewiesen werden. Das – und die Auszeichnung von correspSearch mit dem Berliner DH-Preis 2015 – gab Rückenwind für die Beantragung eines DFG-Projekts. Der Antrag wurde dankenswerterweise positiv beschieden und das Projekt konnte 2017 starten.
Im Rahmen des DFG-Projekts wurde der Prototyp durch eine neue, modularisierte Softwarearchitektur ersetzt, die im Kern vor allem auf die Suchmaschinensoftware Elasticsearch setzt. Dadurch können auch sehr große Mengen an Meta- und Volltext-Daten (zu letzterem siehe weiter unten) performant durchsucht werden. Auch für Harvesting, Ingest und API wurden jeweils neue Applikationen entwickelt, die einen sicheren und stabilen Produktivbetrieb gewährleisten.
Kartenbasierte Suche in correspSearch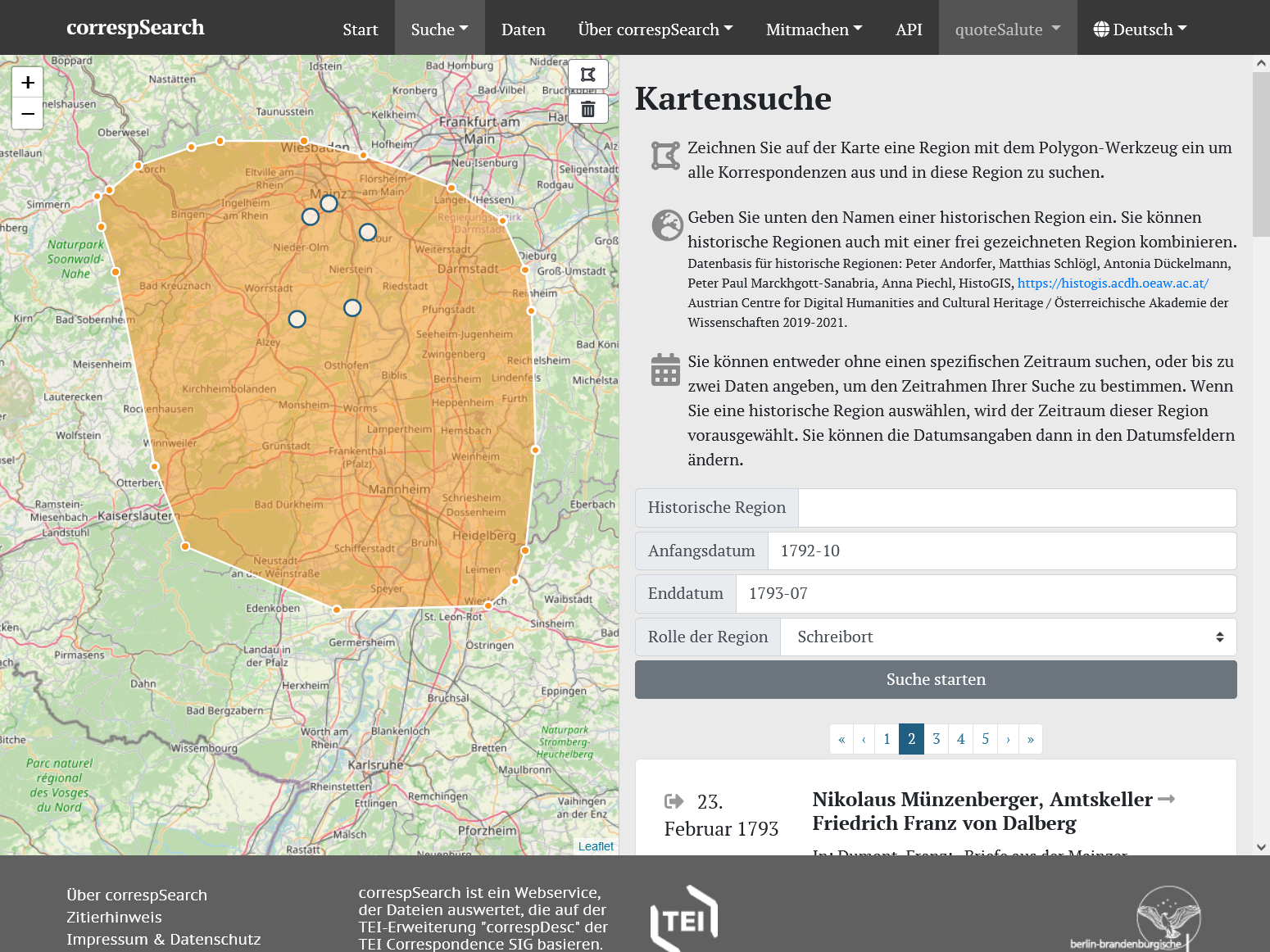{kind=link}
Die Software Elasticsearch ermöglichte auch eine facettierte Suche, so dass Suchergebnisse weiter exploriert und gefiltert werden können. Dabei wurden auch einige Filter entwickelt, die erst durch die Anreicherung der aggregierten CMIF-Daten mit weiteren Normdaten möglich werden. So können jetzt auch Briefe nach Geschlecht sowie Berufen ihrer Korrespondenten:innen recherchiert werden. Dazu nutzt correspSearch Daten aus der Gemeinsamen Normdatei und Wikidata nach. Mit Hilfe der von GeoNames bezogenen Geokoordinaten kann z.B. die kartenbasierte Suche benutzt werden. Hier kann nach Briefen anhand einer Region gesucht werden, die entweder frei eingezeichnet wird oder aus einem in HistoGIS vorgehaltenen, historischem Staatsgebiet (nach 1815) ausgewählt wird. Die neue Suchoberfläche wurde in Vue.js umgesetzt, die Website insgesamt ist nun responsiv und kann daher auf allen Endgeräten genutzt werden.
Erfassungsmaske im CMIF Creator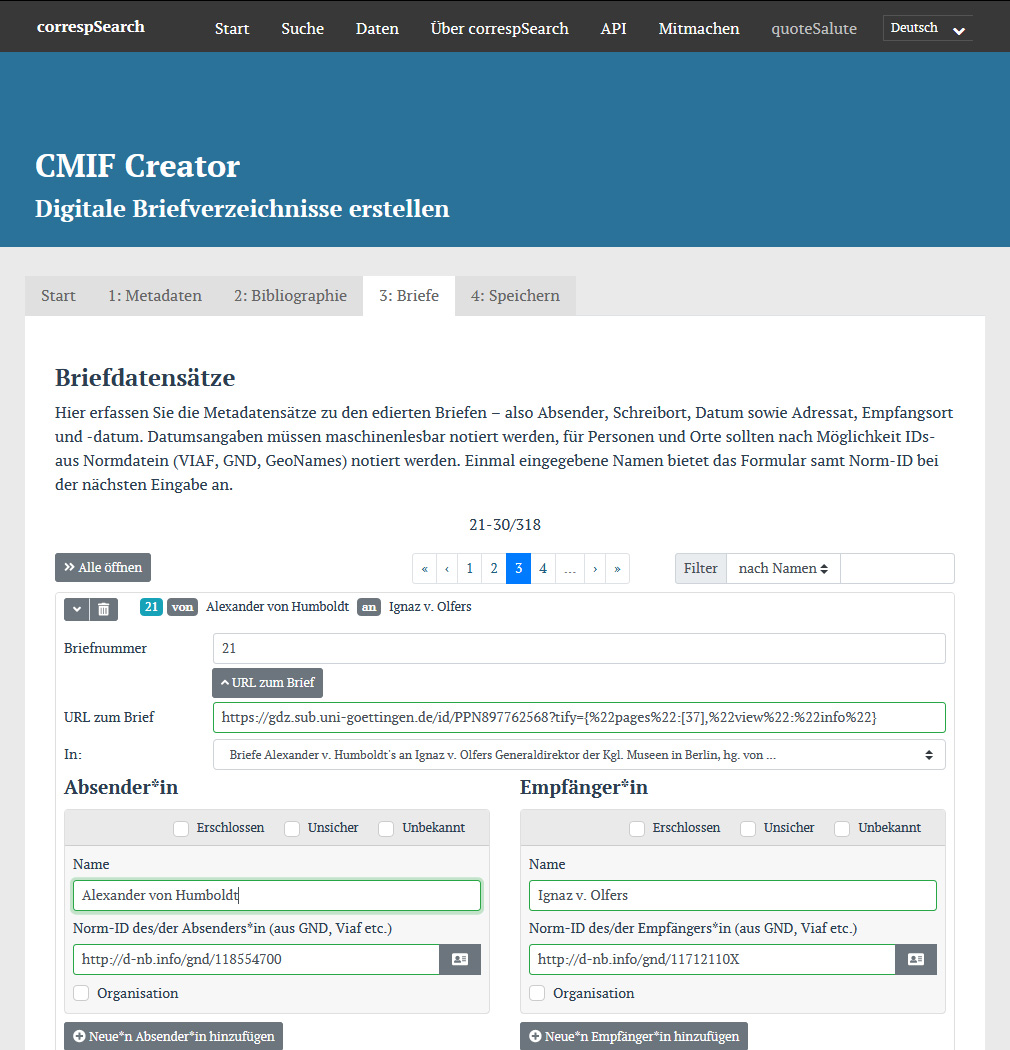{kind=link}
Darüber hinaus wurde mit dem CMIF Creator ein browserbasiertes Eingabeformular geschaffen, mit dessen Hilfe Wissenschafter:innen ohne technische Vorkenntnisse digitale Briefverzeichnisse ihrer Editionen erstellen können. Bei der Eingabe von Personen und Orten kann auch direkt bequem die GND bzw. GeoNames angefragt werden, um Normdaten-IDs für Personen und Orte zu ergänzen. Die Services CMIF Check und CMIF Preview unterstützen die Überprüfung von CMIF-Dateien. Außerdem wurden eigens Erklärvideos zu correspSearch und zum CMIF Creator produziert, die die bereits vorhandene Dokumentation ergänzen. Auch die Community stellte dankenswerterweise Tools für die CMIF-Erstellung bereit: So entwickelte Klaus Rettinghaus das Python-Tool CSV2CMI, das CSV-Tabellen in CMIF-Dateien umwandeln kann. Das Tool wird von der Sächsischen Akademie der Wissenschaften auch als Webservice angeboten – ergänzt um den Dienst ba[sic]?.
Das Widget csLink im Einsatz in der Weber-Gesamtausgabe (unten rechts)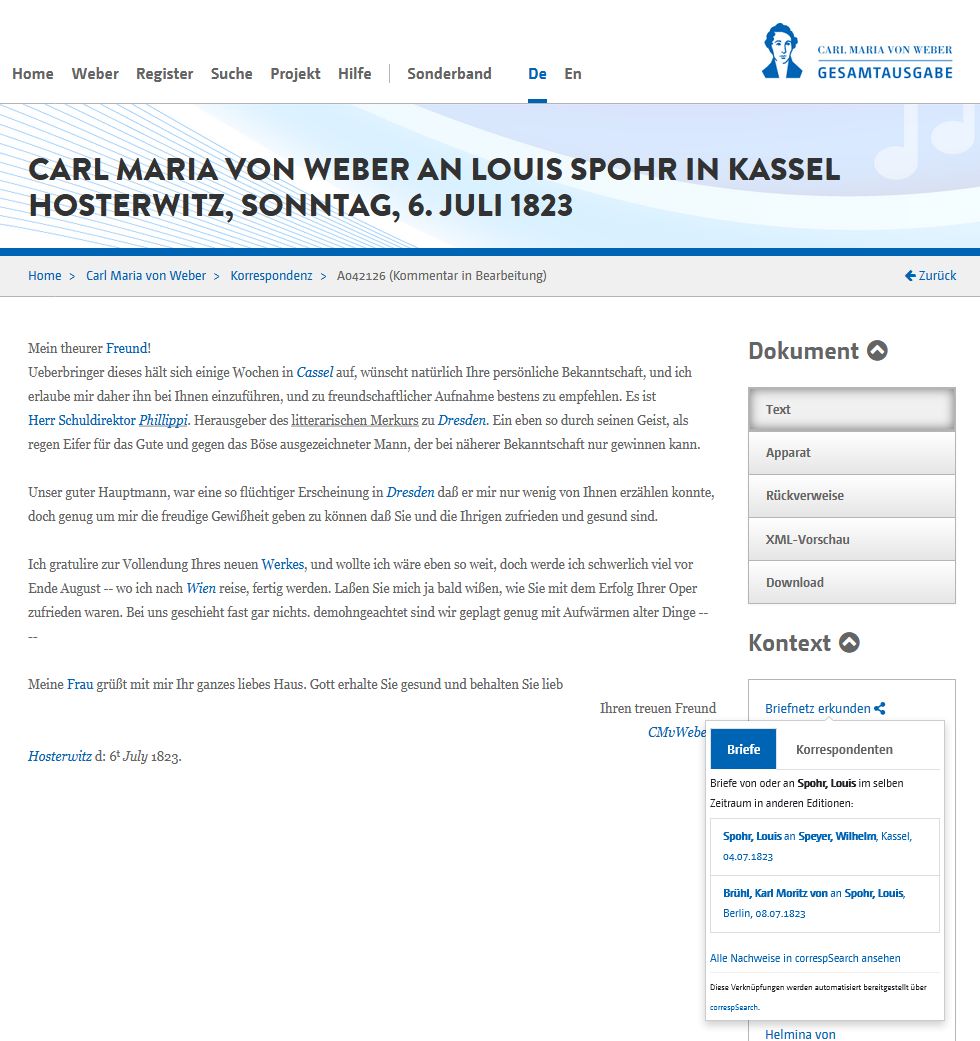{kind=link}
Im DFG-Projekt wurde außerdem das Javascript-Widget csLink entwickelt, das zu einem edierten Brief in der eigenen digitalen Edition auf zeitlich benachbarte Briefe der Korrespondenzpartner:innen aus anderen Editionen hinweist (dafür fragt es die API von correspSearch ab). Dieser ‚erweiterte Korrespondenzkontext‘ kann sehr interessant sein, denn eine Person kann über ein Ereignis etc. an verschiedene Korrespondenzpartner schreiben – und das unter Umständen auch mit unterschiedlichem Inhalt (Dumont 2023, 745). Das Widget csLink ist unter einer freien Lizenz publiziert und kann von jeder digitalen Edition nachgenutzt werden.
2018 kam ein kleines Nebenprojekt hinzu, das von Student:innen initiiert und umgesetzt wurde: quoteSalute (Lou Klappenbach, Marvin Kullick und Louisa Philipp, betreut von Stefan Dumont, Frederike Neuber und Oliver Pohl). Der Dienst quoteSalute bietet kuratierte Grußformeln aus edierten Briefen an, die in der eigenen (E-Mail-)Korrespondenz verwendet werden können (siehe hierzu auch den Artikel im DHd-Blog). QuoteSalute wurde mit dem DARIAH-DE DH-Award 2018 ausgezeichnet. Im selben Jahr wurde zudem der community-getriebene Projektverbund aus correspDesc, CMIF & correspSearch mit dem Rahtz Price for TEI Ingenuity der Text Encoding Initiative ausgezeichnet.
Zufällige Grußformeln mit quoteSalute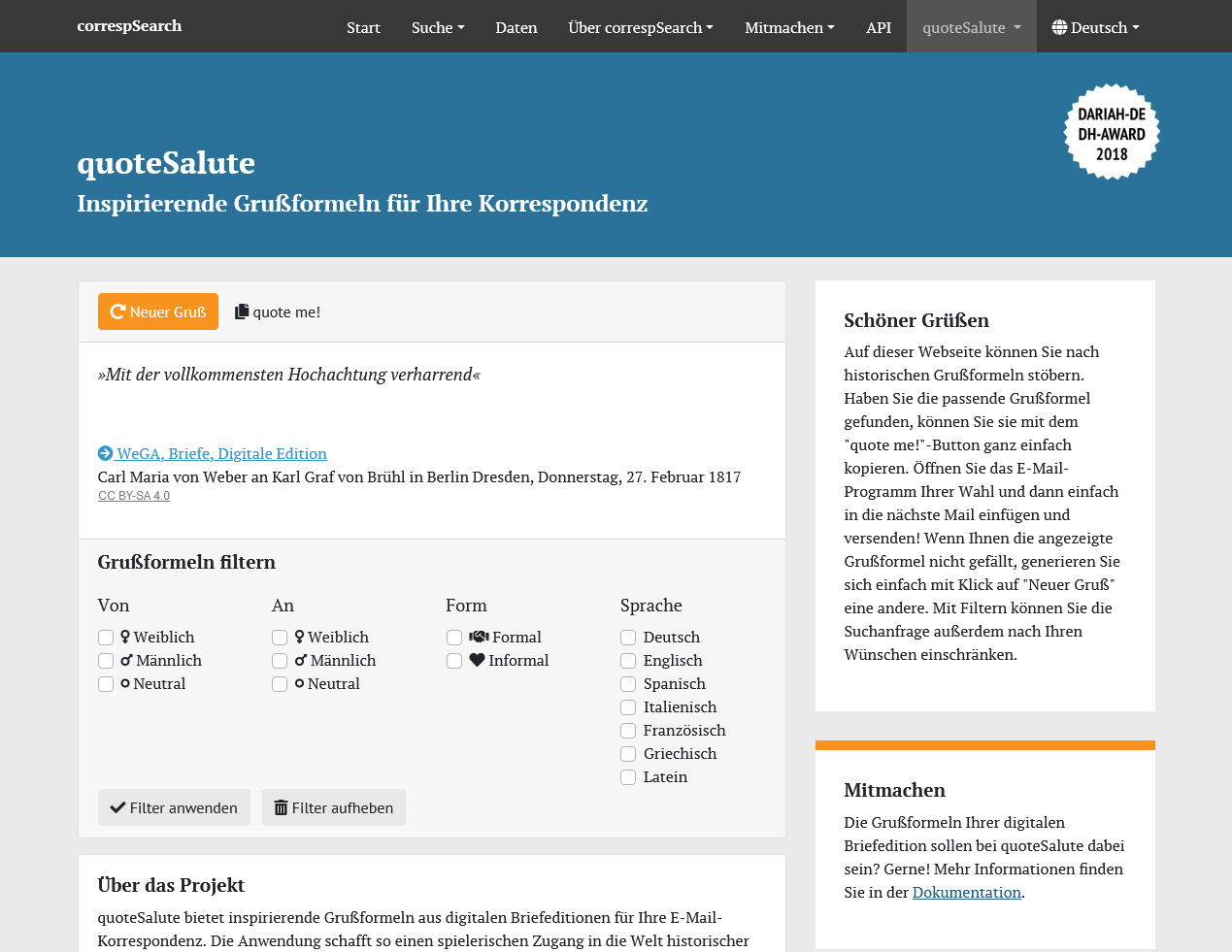{kind=link}
Im Laufe der vergangenen Jahre wuchs die Anzahl der in correspSearch nachgewiesenen Briefe durch zahlreiche Datenbereitstellungen – der größte Teil kam dabei aus der Fachcommunity, d.h. von den Editionsvorhaben und Institutionen selbst. Alle Datenbeiträger aufzuzählen würde den Rahmen dieses Blogbeitrags leider sprengen, aber einige sollen (neben den schon oben genannten) beispielhaft erwähnt werden: Alfred Escher-Briefedition, Alexander Rollett. Seine Welt in Briefen 1844-1903 (ZIM Graz), Briefe der Bach-Familie (Sächsische Akademie der Wissenschaften und Bach-Archiv Leipzig), Arthur Schnitzler – Briefwechsel mit Autorinnen und Autoren (M. A. Müller, G. Susen, L. Untner, ÖAW; nicht nur selbst edierte Briefe, sondern auch Metadaten zu Schnitzler-Briefen in anderen Editionen), Digitale Edition der Korrespondenz August Wilhelm Schlegels (J. Strobel & C. Bamberg), Briefe Friedrich Wilhelm Joseph Schelling 1786-1802 (BAdW), Melanchthon-Briefwechsel (Heidelberger Akademie der Wissenschaften), hallerNet, verschiedene Editionen, die im Rahmen des von Annika Rockenberger geleiteten Projekts Norwegian Correspondences (NorKorr) erfasst bzw. bereitgestellt wurden (z.B. zu Camilla Collet oder Edvard Munch), die Korrespondenz von Otto Nicolai (K. Rettinghaus), Hallesche Pastoren in Pennsylvenia (Franckesche Stiftungen), Briefe an Johann Wolfgang Goethe (Klassik Stiftung Weimar), Briefe von und an Theodor Fontane (Fontane-Archiv Potsdam), die Korrespondenz von Paul d’Estournelles de Constant (Anne Baillot & Team), The Mary Hamilton Papers (D. Denison et al.), das Thomas Gray Archive (R. Eck & A. Hubert), CatCor – The Correspondence of Catherine the Great … die Liste ließe sich fortsetzen. Eine vollständige Übersicht aller CMIF-Dateien bzw. Publikationen kann hier eingesehen werden.
CorrespSearch ist für die aggregierten Daten übrigens keine Einbahnstraße: Der Webservice kann auch – übrigens bereits seit dem Launch 2014 – über APIs abgefragt und die Daten unter einer freien Lizenz maschinenlesbar abgerufen werden. Als Formate stehen TEI-XML, TEI-JSON sowie CSV zur Verfügung – in der API-Dokumentation können die Details eingesehen werden. Darüber hinaus bietet eine BEACON-Schnittstelle die Möglichkeit, die in correspSearch nachgewiesenen Korrespondenzen automatisiert (etwa aus Personenregistereinträgen) zu verknüpfen. Im Herbst 2023 wurde die technisch rundum erneuerte API 2.0 gelauncht, die auch bei großen Abfragen eine gute Performance gewährleistet.
Stand der Dinge: Version 3.0 mit Visualisierungen und Volltextsuche
Vor kurzem konnte das DFG-Projekt erfolgreich abgeschlossen werden und die Version 3.0 des Webservices correspSearch freigeschaltet werden. Damit einhergehend stehen nun auch neue Funktionen bereit. Neben Verbesserungen wie durchsuchbare Facetten, wurden auch zwei grundlegend neue Funktionen eingeführt.
Die (publizierte) Korrespondenz von A. v. Humboldt im Zeitverlauf visualisiert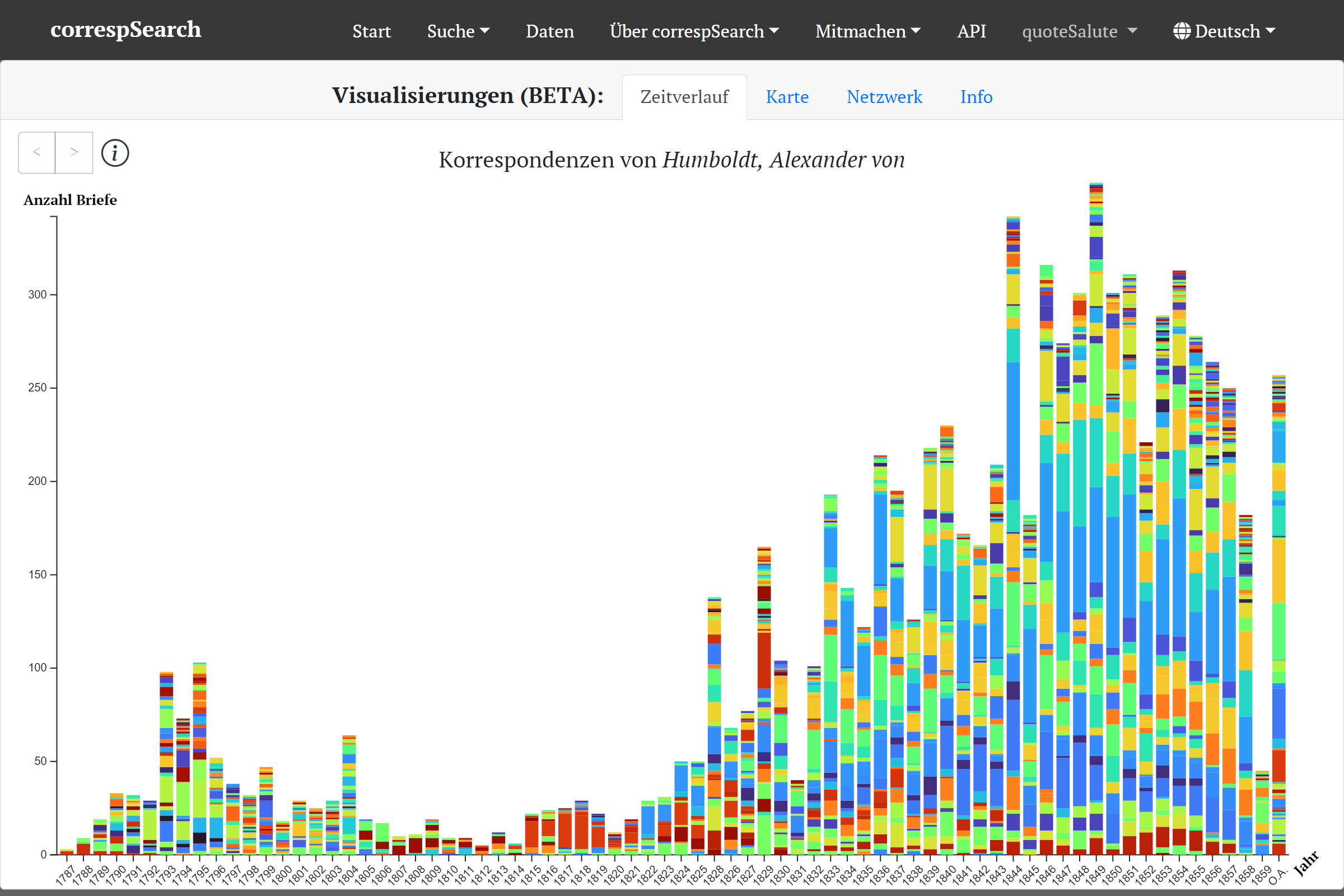{kind=link}
Zum einen können Suchergebnisse nun auch in Visualisierungen exploriert werden. Zur Auswahl stehen drei verschiedene Visualisierungstypen: Zeitverlauf (als gestapeltes Balkendiagramm) der Korrespondenzen, Kartenansicht der Schreib- und Empfangsorte (ebenfalls im Zeitverlauf) und Netzwerkdarstellung der Korrespondenzpartner:innen. Alle drei Visualisierungen können aus dem Suchergebnis heraus (also nach dem Ausführen einer initialen Suche) aufgerufen werden. Je nach Suche eignen sich die verschiedenen Visualisierung unterschiedlich gut für eine weitere Exploration. Während der Zeitverlauf gut für die Darstellung einer Gesamtkorrespondenz ist (etwa die von Constance de Salm-Salm), eignet sich die Kartenansicht besonders gut für Reisekorrespondenzen (etwa die von A. v. Humboldt 1829 in Russland).
Korrespondenznetz aus den Daten der Weber-Gesamtausgabe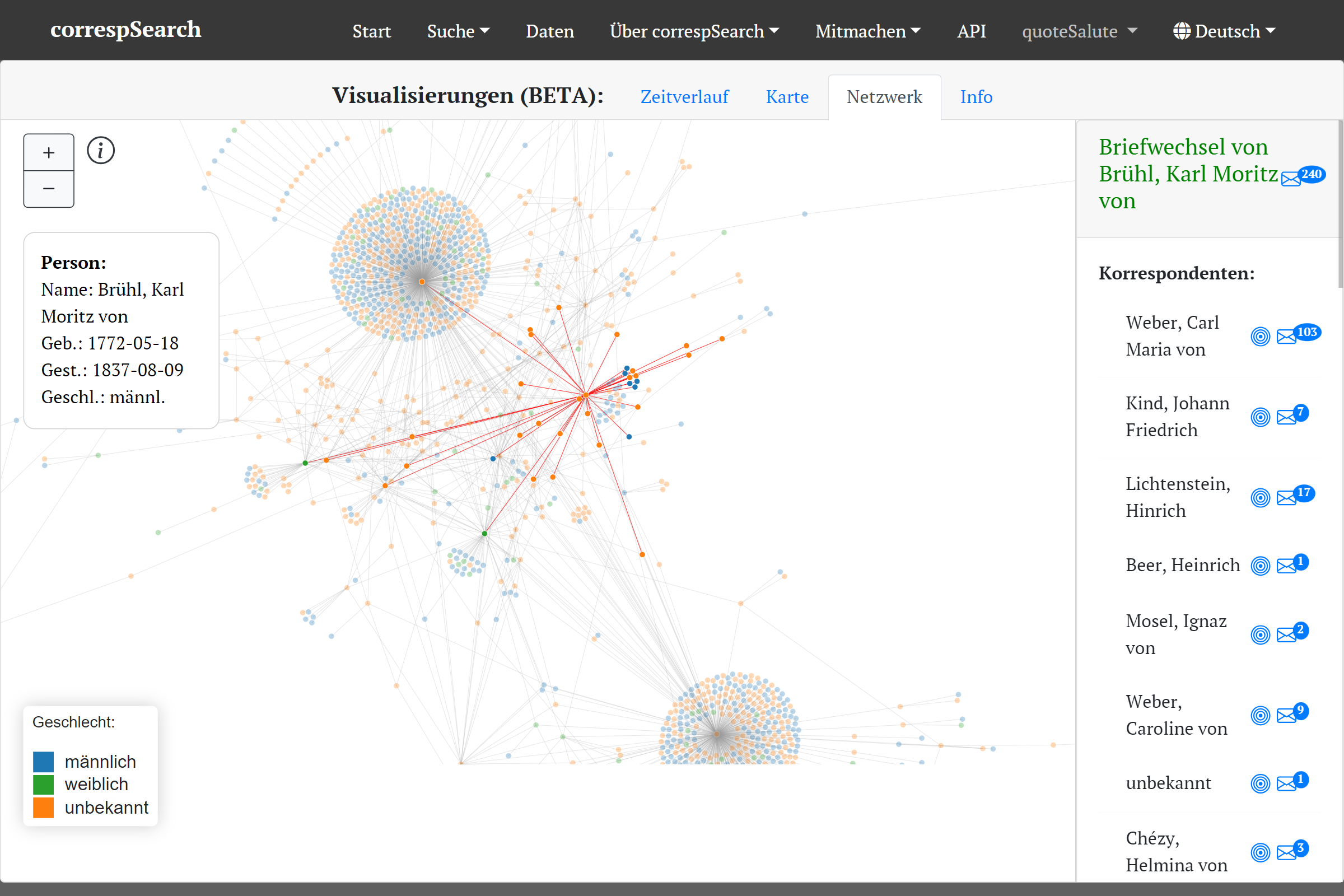{kind=link}
Die Netzwerkansicht dagegen ist interessant für nicht personenzentrierte Abfragen oder Editionen, die auch Briefe Dritter bzw. aus dem Umfeld enthalten (z.B. der Weber-Gesamtausgabe). Außerdem lassen sich mit ihr auch gut Briefnetze und Briefnetzwerke von ganzen Zeitschnitten erkunden (etwa 1789-1798). Allen Visualisierungen kann man durch Zoom-Funktion und Pop-Ups die zugrundeliegenden Metadaten entnehmen. Auch ist ein Wechsel zurück ins Suchergebnis für detailliertere Recherchen an vielen Stellen möglich. Das reibungslose “Switchen” vom Suchergebnis in die Visualisierung und zurück war ein zentraler Punkt im Konzept der Visualisierungen, die mit Hilfe von D3.js umgesetzt wurden.
Trefferanzeige der Suche nach „Jubiläum*“ in correspSearch. Über den Textsnippets ist markiert, ob es sich um Treffer im Regest, dem Brieftext oder dem Herausgeberkommentar handelt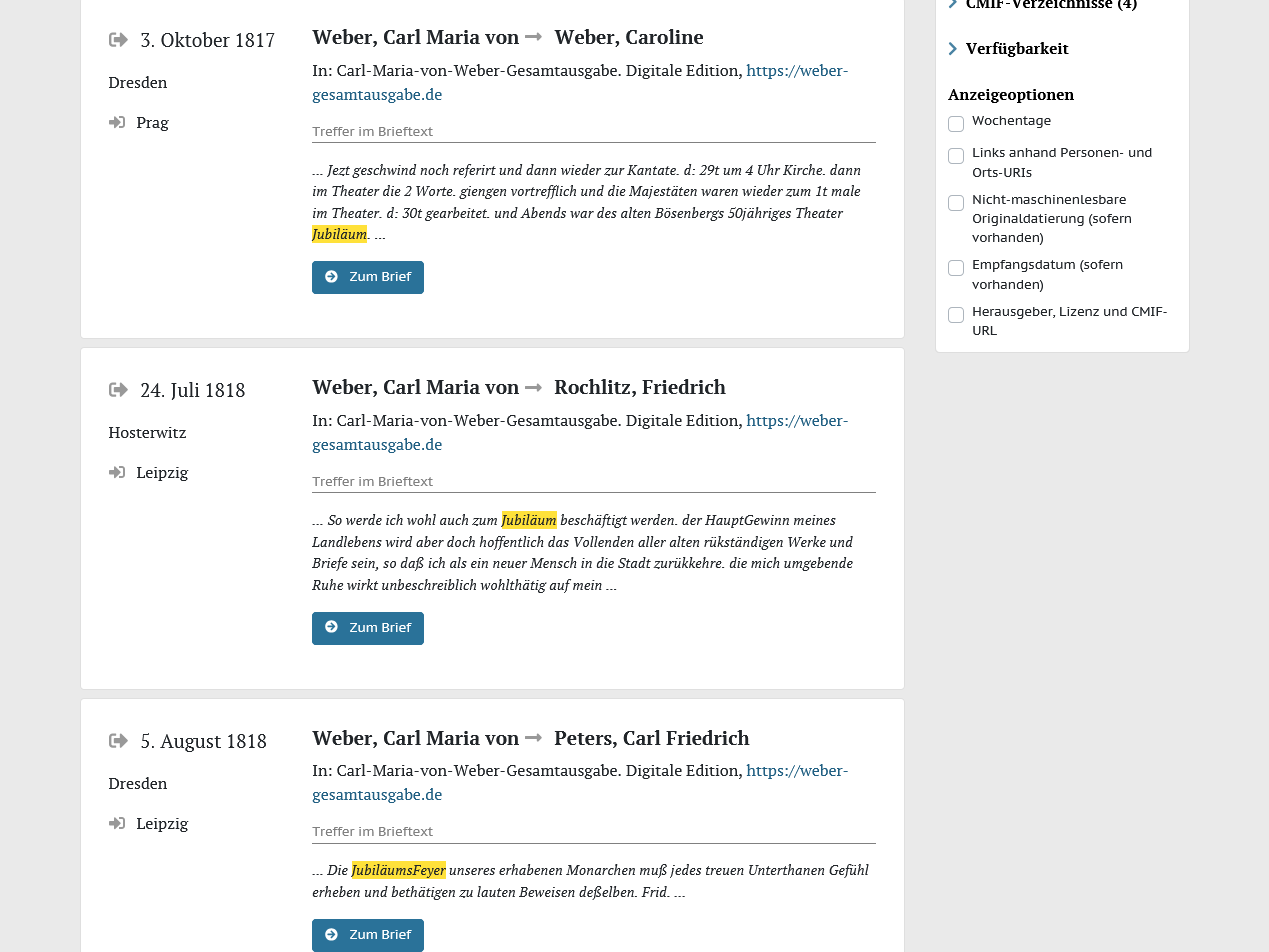{kind=link}
Zum anderen kann correspSearch nun neben den Metadaten auch die Volltexte der edierten Briefe harvesten, aggregieren und zur Recherche bereitstellen (z.B. für eine Suche nach “Jubiläum*”). Dabei wird im CMIF lediglich die URL zum TEI-XML-Volltext des jeweiligen Briefes angegeben und beim Ingest der Metadaten von dort bezogen. Digitale Editionen, die ihre Daten sowieso schon via API anbieten, können so leicht auch die Volltexte für correspSearch bereitstellen. Aber auch der Bezug der einzelnen Dateien aus Datendumps (etwa auf GitHub oder Zenodo) ist technisch grundsätzlich möglich. Beim Ingest werden TEI-Grundstrukturen ausgewertet und im Suchergebnis entsprechend angezeigt: So können Recherchierende Treffer im (originalen) Brieftext von denjenigen im Herausgeberkommentar oder Regest unterscheiden. Derzeit sind nur Texte aus den ersten vier digitalen Editionen recherchierbar, die dankenswerterweise bereits die CMIF-Schnittstelle entsprechend erweitert haben (u.a. Weber-Gesamtausgabe und Dehmel digital). Die Menge der im Volltext durchsuchbaren Briefe werden unter dem Suchschlitz der Volltextsuche angezeigt.
Neben der Volltextsuche werden die Suchfunktionen demnächst auch noch um eine weitere ergänzt: So kann man dann nicht nur nach Korrespondenzpartner:innen suchen, sondern auch nach erwähnten Personen. Die Funktion ist bereits fertig implementiert und wird in Kürze freigeschaltet. Sie basiert – wie die Volltextsuche – auf der Erweiterung des CMIF in Version 2 (Proposal, vgl. auch Dumont et al. 2019).
Mit der Version 3.0 von correspSearch wurde auch die API um eine weitere Schnittstelle erweitert: ab sofort können die Daten auch über einen SPARQL-Endpoint abgefragt werden. Dieser kann dankenswerterweise auf der Plattform lod.academy, die von der Akademie der Wissenschaften und der Literatur Mainz betrieben wird, angeboten werden. Das aktuelle RDF-Datenmodell ist dort ebenfalls dokumentiert. Zu beachten ist, dass der SPARQL-Endpoint derzeit noch als Betaversion betrieben wird und sich auch noch Änderungen am Datenmodell ergeben können.
Der Datenbestand konnte diesen Sommer auch wieder einen neuen Stand erreichen. Vor allem durch die Datenbeiträge aus der Editions- und Forschungscommunity, aber auch aus dem Kooperationsprojekt PDB18 (siehe dazu weiter unten) können aktuell über 270.000 Briefversionen recherchiert werden.
Bleibt alles anders
Das DFG-Projekt correspSearch – Briefeditionen vernetzen ist nun zu Ende gegangen, der Webservice wird aber durch die BBAW dauerhaft weiterbetrieben (BBAW 2023, 6). Außerdem läuft derzeit noch das DFG-Kooperationsprojekt Der deutsche Brief im 18. Jahrhundert (PDB18), das zusammen mit dem Interdisziplinären Zentrum für die Erforschung der Europäischen Aufklärung an der Universität Halle und der ULB Darmstadt durchgeführt wird. Ziel des Projekts ist es, eine Datenbasis und ein kooperatives Netzwerk zur Digitalisierung und Erforschung des deutschen Briefes in der Zeit der Aufklärung aufzubauen. Im Fokus des Projekts steht die Retrodigitalisierung bzw. Metadatenerfassung von gedruckten, abgeschlossenen Briefeditionen (Décultot et al. 2023).
Darüber hinaus wird der Webservice im PDB18-Teilprojekt an der BBAW um einige zusätzliche Funktionen erweitert (z.B. die Filter “Datenset” und “Verwendete Sprache”). Die wichtigste Entwicklung wird allerdings csRegistry werden. Mit csRegistry wird es möglich sein, für einen Brief (als “abstrakte” Entität) eine eindeutige URI zu vergeben und unterschiedliche Editionen dieses Briefes damit zu verknüpfen. Dadurch wird es in Zukunft möglich sein, verschiedene Editionen zu ein und demselben Brief in correspSearch anzeigen zu können bzw. diese “doppelten” Nennungen bei Bedarf aus den Daten herauszufiltern – etwa für die Netzwerkanalyse.
So wird die Zukunft noch ein paar Neuerungen für correspSearch bringen. Hoffentlich aber auch weiterhin viele neue digitale Briefverzeichnisse als CMIF, die den Datenbestand weiter anwachsen lassen. Denn auch wenn schon eine erkleckliche Menge an edierten Briefen in correspSearch nachgewiesen ist, die Masse der insgesamt edierten Briefe (allein im deutschsprachigen Raum) ist noch sehr viel größer. Daher ist auch ein Dienst wie correspSearch ohne die vielen großen und kleinen Datenlieferungen durch Editionsvorhaben, Wissenschaftler:innen und Institutionen nutzlos. Wir möchten uns daher an dieser Stelle für die zahlreichen Datenspenden der letzten 10 Jahre ganz herzlich bedanken. Und wer noch (oder wieder) Daten bereitstellen möchte, findet unter “Mitmachen” auf correspSearch.net alle weiteren Informationen.
Literatur
Berlin-Brandenburgische Akademie der Wissenschaften. 2023. “Das Leitbild Open Science der Berlin-Brandenburgischen Akademie der Wissenschaften.” urn:nbn:de:kobv:b4-opus4-37530.
Décultot, Elisabeth, Stefan Dumont, Katrin Fischer, Dario Kampkaspar, Jana Kittelmann, Ruth Sander und Thomas Stäcker. 2023. “PDB18: The German Letter in the 18th Century.” [Poster]. Encoding Cultures – Joint MEC and TEI Conference. Paderborn 2023. https://hcommons.org/deposits/item/hc:59731/
Dumont, Stefan. 2018. “correspSearch – Connecting Scholarly Editions of Letters.” Journal of the Text Encoding Initiative 10. https://doi.org/10.4000/jtei.1742.
Dumont, Stefan, Ingo Börner, Jonas Müller-Laackman, Dominik Leipold, Gerlinde Schneider. 2019. Correspondence Metadata Interchange Format (CMIF). In: Encoding Correspondence. A Manual for Encoding Letters and Postcards in TEI-XML and DTABf. Hg. v. Stefan Dumont, Susanne Haaf, and Sabine Seifert. URL: https://encoding-correspondence.bbaw.de/v1/CMIF.html URN: urn:nbn:de:kobv:b4-20200110163712891-8511250-2
Dumont, Stefan. 2023. “Briefeditionen vernetzen.” In Digitale Literaturwissenschaft: DFG-Symposion 2017, edited by Fotis Jannidis, 729–49. Germanistische Symposien. Stuttgart: J.B. Metzler. https://doi.org/10.1007/978-3-476-05886-7_30.
Stadler, Peter. 2014. “Interoperabilität von Digitalen Briefeditionen.” In Fontanes Briefe Ediert, edited by Hanna Delf von Wolzhagen, 278–87. Fontaneana 12. Würzburg: Königshausen & Neumann.
Stadler, Peter, Marcel Illetschko, and Sabine Seifert. 2016. “Towards a Model for Encoding Correspondence in the TEI: Developing and Implementing <correspDesc>.” Journal of the Text Encoding Initiative [Online] 9. https://dx.doi.org/10.4000/jtei.1742.
Credits für Grafik „Birthday Cake“ in der Beitragsvorschau dieses Artikels: The Noun Project. CC BY 3.0. https://thenounproject.com/icon/birthday-cake-692475/
Die Vernetzung von Akteuren und Ressourcen – OER in der NFDI und in den Datenkompetenzzentren: ein Workshopbericht
Autor:innen: Jonathan D. Geiger; Katharina Bergmann; Johanna Konstanciak; Marina Lemaire; Andrea Polywka; Ruth Reiche; Sibylle Söring; Anne Voigt
Lehr-Lernmaterialien (Open Educational Resources, OER) zur Entwicklung von Data Literacy und Kompetenzen im Forschungsdatenmanagement (FDM) sind in der Nationalen Forschungsdateninfrastruktur (NFDI) und darüber hinaus ein zentrales Thema. Die meisten FDM-Projekte und -Netzwerke sammeln und/oder produzieren OER und setzen sich dabei mit Fragen nach der Verstetigung, der Sammlung, der Kuratierung und der Verknüpfung auseinander. Die FAIR-Prinzipien sind hier genauso anwendbar wie auf Forschungsdaten.
Vor diesem Hintergrund fanden sich am 22. und 23. April 2024 Vertreter*innen der NFDI-Konsortien NFDI4Culture, NFDI4Memory, der Datenkompetenzzentren QUADRIGA und HERMES und des Infrastrukturprojekts der NFDI-Sektion Training & Education – DALIA – in der Akademie der Wissenschaften und der Literatur Mainz zu einem gemeinsamen Workshop zusammen. Die Projekte präsentierten ihre jeweiligen Arbeitsstände und im Anschluss wurden in interaktiven Formaten Kollaborationsmöglichkeiten, Synergieeffekte und zentrale Diskussionspunkte ausgelotet.
Gruppe der Workshopteilnehmenden am 23.4.2024 (Foto: Aglaia Schieke){kind=link}
Das NFDI-Konsortium NFDI4Culture (Projektlaufzeit 2020–2025) hat einen Dienst vorgestellt, der eine Auswahl an OER bereitstellt, die sich an die geistes- und kulturwissenschaftlichen Communities richten und sowohl generische als auch fachspezifische Angebote zu Forschungsdatenmanagement und Datenkompetenzen beinhalten. Im Vorfeld hat das Team der “Cultural Research Data Academy” in ausgewählten Veranstaltungen und Formaten die Bedarfe der NFDI4Culture Communities abgefragt, in einem Portfolio gesammelt und mit ausgewählten Qualitätskriterien evaluiert. Daraus entstand der “Educational Resource Finder” (ERF), eine kuratierte Auswahl an deutsch- und englischsprachigen Schulungs- und Weiterbildungsangeboten, die sich an Interessierte aller Wissensstufen richten und fortwährend aktualisiert werden.
Das NFDI-Konsortium NFDI4Memory (Projektlaufzeit 2023–2028) stellte seine Arbeitspakete der Task Area “Data Literacy” im Bereich OER vor. Die Task Area hat zur Aufgabe die Datenkompetenzen in Forschung und Lehre der historisch arbeitenden Disziplinen zu verbessern. Dafür werden u. a. ein Data-Literacy-Trainingskatalog mit didaktischen und inhaltlichen Empfehlungen erstellt sowie zielgruppenspezifische Trainingsmodule entwickelt. Die Inhalte des Trainingskatalogs werden durch eigene Recherchen, selbstentwickelte Materialien sowie durch eine Erhebung in der Community zusammengetragen. Anschließend werden die Informationen in einem in Entwicklung befindlichen Workflow für die Online-Präsentation und Suche aufbereitet.
Das vom BMBF geförderte Datenkompetenzzentrum QUADRIGA (Projektlaufzeit 2023-26) vereint die vier Disziplinen Digital Humanities, Verwaltungswissenschaft, Informatik und Informationswissenschaft entlang der Datentypen Text, Tabelle und Bewegtes Bild am Wissenschaftsstandort Berlin-Brandenburg. Auf der Grundlage von Fallstudien erarbeitet das Zentrum interaktive Lehrbücher (Jupyter Notebooks), die QUADRIGA Educational Resources (QER), die modular aufgebaut sind, und die die Lernzielkontrolle mittels eines Assessments ermöglichen. Workflows – insbesondere das Zusammenspiel mit dem QUADRIGA Space sowie dem QUADRIGA Navigator – und beispielhafte Ausgestaltungen wurden im Rahmen des Workshops von Zhenya Samoilova, Sonja Schimmler und Bettina Buchholz vorgestellt. Für das Teilprojekt Verstetigung nahm Sibylle Söring teil.
Das Datenkompetenzzentrum HERMES (Humanities Education in Research, Data, and Methods), gefördert vom BMBF (Projektlaufzeit 2023–2026), hat das Ziel, Datenkompetenzen im Bereich der Geistes- und Kulturwissenschaften zu vermitteln und weiterzuentwickeln. Anwesend bei dem Workshop waren die Mitarbeiter:innen der HERMES-Formate „Open Educational Resources“ und „HERMES-Hub“: In HERMES werden sowohl OER erstellt als auch in einer Ressource Base aggregiert. Hierfür wird eine Metadatenempfehlung entwickelt, die auf einem projektübergreifenden Metadaten-Basisschema aufbauen soll. HERMES legt dabei besonderen Wert auf die Verschlagwortung der Ressourcen mit der TaDiRAH-Taxonomie, um nach Forschungsmethoden filtern zu können. Forschende wird das HERMES-Team zudem in der Konzeption und Umsetzung von OER-Materialien beratend unterstützen.
Das Projekt DALIA ist ein vom BMBF gefördertes Infrastrukturprojekt (Laufzeit 2022–2025) der Sektion Training und Education (EduTrain) der Nationalen Forschungsdateninfrastruktur. Das Projektziel ist der Aufbau eines Knowledge Graphen für Data-Literacy- und FDM-Kompetenz-bezogene OER. Dabei sollen auch Akteure des Feldes zusammengebracht und ihre Vorarbeiten und Bedarfe erhoben und berücksichtigt werden. Der Knowledge Graph ist Grundlage einer Plattform, über die OER von Nutzer*innen gefunden und von Autor*innen verzeichnet werden können.
Ergebnisse des WorkshopsAls zentrale Herausforderungen für die weitere Harmonisierung der Projekt-Arbeitsprozesse wurden insbesondere drei Handlungsfelder identifiziert:
- Metadaten und Interoperabilität von OER (Materialien und Repositorien)
- Nachhaltigkeit
- Kooperationen
Brainstorming-Ergebnisse 1. Tag (Foto: Simon Donig)
Metadaten und Interoperabilität: Um OER gemäß der FAIR-Prinzipien zu gestalten, muss sich deren Beschreibung (Metadaten) an Normdaten und kontrollierten Vokabularen orientieren. Für OER liegen verschiedene Metadatenstandards vor, insgesamt liegt die Herausforderung aber im Spagat zwischen vorhandenen Standards und den eigenen Bedarfen, die sich zwischen den Polen der eigenen Kapazitäten, technischen Rahmenbedingungen und Bedarfen der jeweiligen Community aufspannen. Synergien ergeben sich aus einem gemeinsam entwickelten Applikationsprofil sowie die gemeinsame Evaluation des DALIA OER-Metadatenbasisschema “DALIA Interchange Format” (DIF). Weitere Potenziale für Kooperationen liegen in der Anfertigung von Fallstudien, Schulungen und Bedarfsanalysen.
Ergebnisse Ermittlung des IST-Zustandes zum Themenfeld „Metadaten“ (Foto: Simon Donig)
Nachhaltigkeit: Das Thema Nachhaltigkeit von Infrastrukturangeboten umfasst verschiedene Ebenen. Klar ist, dass ein Dienst keinen langfristigen Bestand haben kann, der nicht nachhaltig organisiert und dauerhaft finanziert wird. Neben den Betriebsmodellen ist auch die Verwendung offener Datenstandards notwendig, um die Abhängigkeiten von proprietären Formaten und Werkzeugen zu reduzieren. Die Teilnehmenden des Workshops konzentrierten sich allerdings auf einen dritten Aspekt von Nachhaltigkeit: Die Akzeptanz und Nutzung des Angebotes durch die Community. Für die Akquirierung von finanziellen Ressourcen bedarf es einer nachweislichen Relevanz des Angebots für die jeweilige Fachcommunity. Diese muss beispielsweise über Zugriffs- oder Downloadzahlen sowie Interaktionen mit den Betreibenden nachgewiesen werden. Wie die Zielgruppen angesprochen und gehalten werden können, eine konkrete OER-Plattform zu nutzen, ist eine offene Frage. Dabei spielt selbstverständlich die optimale Bedienung der Bedarfe eine große Rolle, jedoch sind diese im vollen Umfang noch nicht bekannt. So wurde festgestellt, dass insbesondere die Bedarfe der Lehrenden und ihr OER-Nutzungsverhalten weniger bekannt sind.
Kooperationen: Das dritte Themencluster bestand in Überlegungen zur weiteren Kooperationen der am Workshop beteiligten Personen und Projekte. Neben den im Bereich Metadaten und Nachhaltigkeit diskutierten Maßnahmen wie Use Cases und synoptische Metadatenschema-Vergleiche zwischen den Projekten, wurden mehrere nachfolgende Meetings sowie ein Anschlussworkshop für das Frühjahr 2025 vereinbart. Wo möglich, soll Doppelarbeit vermieden werden, sowie der Austausch zwischen den Projekten erhalten bleiben.
Ergebniszusammenfassung zu welchen Themenbereichen die Gruppe zusammenarbeiten möchte (Foto: Simon Donig)
Zusammenfassend lässt sich festhalten, dass es große Überschneidungen der Arbeitsprogramme aller Workshop-Beteiligten (NFDI-Konsortien und Datenkompetenzzentren) gibt und der Diskurs durch gemeinsame Veranstaltungen nicht nur fruchtbarer wird, sondern auch Doppelarbeit identifiziert und reduziert werden kann. Ebenfalls wurde offensichtlich, dass quasi sämtliche Aspekte (Metadaten, Förderung, Community-Akzeptanz etc.) eng miteinander gekoppelt und aufeinander bezogen sind. Dementsprechend wurde eine Reihe nächster Schritte geplant – neben weiteren Meetings zum Austausch zu den Metadatenprofilen insbesondere ein Anschlussworkshop, in dem der Kreis der beteiligten FDM-Projekte aus dem Umkreis der Geistes- und Sozialwissenschaften noch erweitert werden soll.
Call for Hosts DHd 2027
DHd20xx ist die jährliche, internationale Fachtagung der Digital Humanities im deutschsprachigen Raum (DHd, http://dig-hum.de) und die führende wissenschaftliche Konferenz für die Digital Humanities im deutschen Sprachraum. Die erste Tagung fand 2014 an der Universität Passau statt, die weiteren Stationen waren 2015 an der Karl-Franzens-Universität Graz, 2016 an der Universität Leipzig, 2017 an der Universität Bern, 2018 an der Universität zu Köln, 2019 an den Universitäten Mainz und Frankfurt /Main und 2020 an der Universität Paderborn. Pandemiebedingt wurde die DHd2021 um ein Jahr verschoben. Die DHd2022 wurde von der Universität Potsdam und der Fachhochschule Potsdam virtuell durchgeführt, die DHd2023 wurde gemeinsam von den Universitäten Trier und Luxemburg ausgerichtet und die DHd2024 fand an der Universität Passau statt. Der Ausrichtungsort der DHd2025 wird die Universität Bielefeld und der Ausrichtungsort der DHd2026 die Universität Wien sein.
Der Fachverband Digital Humanities im deutschsprachigen Raum bittet nun um Bewerbungen um die Ausrichtung für die dreizehnte Tagung (DHd2027).
Die Konferenzen haben bis zu 650 Teilnehmerinnen und Teilnehmer aus dem deutschsprachigen Raum und angrenzenden Ländern angezogen. Die Tagungsprogramme sahen jeweils zwei Tage für Workshops und drei Tage für das Hauptprogramm bestehend aus Keynotes, parallelen Sektionen mit wissenschaftlichen Vorträgen, Paneldiskussionen, Posterpräsentationen und Doctoral Consortia vor. Die Einführung neuer Formate ist in Abstimmung mit dem Verband und dem Programmkomitee möglich.
Das wissenschaftliche Programm der Tagung wird durch ein vom Fachverband eingesetztes internationales Programmkomitee auf Grundlage eines Call for Papers und eines anschließenden Review-Verfahrens erstellt. Das Konferenzprotokoll des DHd-Verbands muss berücksichtigt werden.
Die Tagung finanziert sich über Teilnahmegebühren und von der ausrichtenden Institution bereitgestellte oder über Partner:innen oder Sponsor:innen eingeworbene finanzielle Mittel. Die erhobene Tagungsgebühr ist mit dem Vorstand des Fachverbandes abzustimmen und soll vier Kategorien umfassen: reguläre und ermäßigte Mitglieder des DHd (letztere im Sinne der Regelung zur ermäßigten Mitgliedschaft im DHd-Verband) sowie reguläre und ermäßigte Nicht-Mitglieder des DHd. Die Tagungsgebühr muss für Nicht-Mitglieder mindestens die Tagungsgebühr für Mitglieder des DHd zuzüglich des Mitgliedsbeitrags plus 5 Euro betragen, wobei die jeweils relevante Beitragskategorie berücksichtigt werden muss.
Die Bewerbung um die Ausrichtung der DHd2027 soll umfassen:
- einen Vorschlag für ein Tagungsmotto sowie zwei Terminvorschläge (bevorzugt im Zeitraum Februar bis März). Bei der Terminplanung soll auf potentiell konkurrierende Konferenzen, Semesterzeiten und Feiertage sowie Schulferien geachtet werden.
- einen Überblick über die für die Konferenz bereitgestellte Infrastruktur (vor allem Tagungsräume für Workshops, AG-Sitzungen, parallele Sektionen und Plenarveranstaltungen)
- Aussagen über die Unterstützung der Ausrichtung vor Ort (z.B. durch die Universitätsleitung)
- eine Aussage über die Verwendung von Management- und Bezahlsystemen (das System Conftool ist dafür etabliert und soll zumindest für die Einreichungen genutzt werden)
- eine Aussage über die Unterstützung der Publikation der Tagungsbeiträge in Kooperation mit dem Data Stewart des DHd-Verbands
- Angaben zur Erreichbarkeit des Tagungsortes (bzw. ggf. der Tagungsorte) und die Verfügbarkeit von Unterkünften (inkl. Preisschätzungen)
- eine Einschätzung zu den Möglichkeiten einer teilweisen virtuellen Partizipation
- Ideen für Social Events
- Vorschläge zur Erreichung einer hohen Sichtbarkeit der Tagung
- Maßnahmen zur Förderung von Nachwuchswissenschaftler:innen (inkl. Studierende)
- eine vorläufige Kostenkalkulation und Vorstellungen über die Tagungsgebühr
- ggf. Preiskonzept bei Planung einer vollständigen Hybridkonferenz
- eine Erklärung, dass die Konferenz entsprechend der im Konferenzprotokoll dargelegten Bedingungen ausgerichtet wird
Bewerbungen werden bis 30.11.2024 entgegen genommen (formlos per E-Mail an die Tagungskoordinatorin im Vorstand des Fachverbandes, Lisa Dieckmann: lisa.dieckmann@uni-koeln.de). Interessierte Ausrichter:innen werden gebeten möglichst frühzeitig, in jedem Falle aber vor Einreichung ihrer Bewerbung, mit Lisa Dieckmann Kontakt aufzunehmen. Die Bewerbung sollte zehn Seiten möglichst nicht überschreiten. Die Vergabe der Tagung erfolgt durch den Vorstand des Fachverbandes bis spätestens 31.01.2025.
Hybrid-Workshop: „Literatur und Raum“ am 01.10.2024
Seit den 1980er Jahren hat sich das Augenmerk der Kultur- und Sozialwissenschaften international zunehmend auf das Thema Raum gerichtet. Der Geograf Edward Soja lieferte für diese Entwicklung das intuitiv verständliche Label: spatial turn. Anhand der Frage jedoch, was Raum ist und wie er untersucht werden kann, ist in den letzten 40 Jahren eine ganze Landschaft an fachlichen Antworten entstanden.
Der Workshop „Literatur und Raum“ lädt alle Interessierten ein, diese Landschaft auf dem Feld der Literaturwissenschaft zu durchstreifen. Dabei richten wir den Blick insbesondere auf die Methodenvielfalt zwischen close und distant reading, zwischen qualitativen und quantitativen Ansätzen, analogen und computergestützten Verfahren. Welche Begriffe von Raum gibt es im Zusammenhang mit Literatur? Was kann man über Literatur erfahren, wenn man Raum in und um Literatur untersucht? Welcher Ansatz bringt welchen Erkenntnishorizont mit sich?
Die Teilnehmer:innen sind eingeladen, eigene Texte mitzubringen: Neben der theoretischen Diskussion wird es einen praktischen Hands-On-Teil geben, in dem Tools der Computational Literary Studies ausprobiert werden.
Referent:innenWir freuen uns, Prof. Dr. Berenike Herrmann (Universität Bielefeld), Dr. Jana-Katharina Mende (Martin-Luther-Universität Halle-Wittenberg) und Daniel Kababgi (Universität Bielefeld) vor Ort und online begrüßen zu dürfen. Sie werden aus erster Hand von ihren Erfahrungen aus ihren Forschungsprojekten berichten.
TerminDer Workshop findet als Hybrid-Veranstaltung am 01. Oktober 2024 (dienstags) von 09:00 bis 17:00 Uhr statt.
TeilnahmeBitte melden Sie sich über das Online-Formular auf folgender Seite an: https://tinyurl.com/5cnf7dth.
Nach erfolgreicher Anmeldung erhalten Sie die Zugangsdaten für Zoom sowie Informationen zum Programmablauf.
Die Teilnahme ist kostenlos. Die Organisation und die Kosten der Reise, Unterbringung und Verpflegung tragen die Teilnehmenden selbst. Eine Teilnahmebestätigung stellen wir Ihnen auf Wunsch gerne nach der Veranstaltung aus.
Veranstaltungsort in PräsenzUniversität Rostock · Institut für Germanistik
Jakobi-Passage · Seminarraum 9 (4. OG)
Kröpeliner Str. 57
18055 Rostock
Gefördert und organisiert wird der Workshop von der Juniorprofessur für Digital Humanities am Rostocker Institut für Germanistik sowie vom Forschungsschwerpunkt ‚Digitale Hermeneutik’ des Departments „Wissen – Kultur – Transformation“ an der Interdisziplinären Fakultät der Universität Rostock.
Insbesondere an der Organisation beteiligt sind Fernanda Alvares Freire, Nils Kellner, Marc Lemke und Nico Förster.
KontaktFür etwaige Rückfragen wenden Sie sich bitte an Herrn Nils Kellner unter nils.kellner@uni-rostock.de.