dhd-blog
Zum Open Peer Review freigegeben: Die Empfehlungen der DHd-AG Greening DH zum ressourcenschonenden Umgang mit Forschungsdaten sind jetzt online
Nach ihrem Beitrag zum DHCC Toolkit sowie Workshops auf den DHd-Jahrestagungen 2023 und 2024 stellt nun die DHd-AG Greening DH ihre Empfehlungen zum ressourcenschonenden Umgang mit Forschungsdaten vor – diesmal in deutscher Sprache.
Mit dieser Handreichung möchten wir allen geisteswissenschaftlichen Forschenden Hilfestellung im Umgang mit Forschungsdatenmanagementplänen an die Hand geben. Der Fokus auf FDM-Pläne hat sich aus der Feststellung ergeben, dass es sich dabei um eines der wenigen Tools handelt, das die Frage nach dem Umgang mit Ressourcen und damit unseren ökologischen Fussabdruck im Umgang mit Daten, Tools und Softwares thematisiert. Dies erfolgt aber meist implizit. Uns geht es mit den Empfehlungen darum, das Implizite explizit zu machen, für ökologische Fragen unseres Tuns zu sensibilisieren und zugleich darin zu unterstützen.
Die Empfehlungen sind in die sechs Bereiche Formate/Interoperabilität, Versionierung, Metadaten, Nutzungsszenarien und Speicherplatz/Langzeitarchivierung aufgeteilt. Diese haben sich aus dem Workshop „Der Weg zum grünen Forschungsdatenmanagementplan“ auf der DHd 2024 ergeben. In jedem dieser Bereiche werden klassische FDM-Pläne-Fragen in Hinsicht auf ihre Bedeutung für einen schonenden Umgang mit Ressourcen beleuchtet. Auf einige best practices wird ebenfalls hingewiesen.
Die DHd-Community besitzt wie keine andere das Know-How, um diese Empfehlungen soweit zu verbessern, dass sie auch für weniger digital affine Geisteswissenschaftlerinnen und Geisteswissenschaftler hilfreich sein können. So laden wir alle ein, jetzt mitzuwirken. Die aktuelle Version, ist durch das hypothes.is-Interface kommentierbar. Bis zum 31. August ist die Open Peer Review-Phase offen. Wir freuen uns auf zahlreiche, kritisch-konstruktive Kommentare unter diesem Link.
DH-Professuren im deutschsprachigen Raum visualisiert
Jan Horstmann (Universität Münster), Christof Schöch (Universität Trier)
Die Etablierung der Digital Humanities lässt sich anhand mehrerer Merkmale beobachten und analysieren, z.B. der Publikation DH-bezogener Forschungsbeiträge, der Bewilligung und Förderung von DH-Projekten, der Etablierung von Studiengängen mit Anteilen von oder explizitem Fokus auf DH, der Gründung von DH-Forschungszentren und – last but not least – der Ausschreibung und Besetzung von DH-Professuren. Für den deutschsprachigen Raum hat sich Patrick Sahles laufend aktualisierter Blogbeitrag „Professuren für Digital Humanities“ (https://dhd-blog.org/?p=11018; Zugriff: 08.07.2024) als eine zentrale Anlaufstelle herauskristallisiert: Er verzeichnet die seit 2008 ausgeschriebenen DH- (oder DH-bezogenen) Professuren im deutschsprachigen Raum, derzeit 139 an der Zahl. In quantitativer Hinsicht lässt sich dort ein guter Überblick gewinnen, etwa wie viele DH-Professuren pro Jahr ausgeschrieben wurden (bislang ist das Jahr 2021 mit 16 Ausschreibungen der Titelverteidiger).
Was dort fehlt, ist die Möglichkeit, die DH-Professuren im deutschsprachigen Raum auch in örtlicher und zeitlicher Indizierung in den Blick zu nehmen und dadurch verschiedene Fragen leichter zu beantworten, darunter: Welche Orte haben sich wann als DH-Standorte etabliert, indem sie eine oder mehrere DH-Professuren ausgeschrieben haben? Wo sind wann mehrere Professuren entstanden? Wo sind befristete Professuren nicht dauerhaft eingerichtet worden? Und vieles mehr. All dies kann eine interaktive, dynamische Kartenvisualisierung übersichtlich darstellen. Die dafür nötige Art der Zeit-Raum-Visualisierung ist im DARIAH-DE Geo-Browser (https://de.dariah.eu/geobrowser; Zugriff: 08.07.2024) anders möglich als etwa in Wikidata, weshalb wir die Sahle’schen Daten für die Anzeige in diesem Tool aufbereitet haben – und versuchen werden, sie zukünftig regelmäßig zu aktualisieren.1
Link zum Datensatz: https://geobrowser.de.dariah.eu/edit/index.html?id=EAEA0-B2E1-D8CE-AA03-0
Link zur Visualisierung: https://geobrowser.de.dariah.eu/index.html?csv1=https://cdstar.de.dariah.eu/dariah/EAEA0-B2E1-D8CE-AA03-0
Mit dem Fokus auf die raumzeitliche Verortung von DH-Professur-Ausschreibungen im deutschsprachigen Raum setzen wir einen etwas anderen Akzent als verwandte Projekte wie etwa: Mapping the Digital Humanities (Christof Schöch, Mapping the Digital Humanities, v0.1.0, March 2024. Digital Humanities Trier. URL: https://dhtrier.quarto.pub/dhmap/; Zugriff: 08.07.2024) oder Till Grallerts Vorstöße mit Daten aus Wikidata (vgl. https://digitalcourage.social/@tillgrallert/112575546388768661; Zugriff: 08.07.2024).
Methode und BeispieleIm Folgenden erläutern wir die methodischen Entscheidungen, die unserer Visualisierung zugrunde liegen. Prinzipiell erbt unsere Darstellung freilich die Data-capture-Entscheidungen, die bereits die Liste im Blogbeitrag Patrick Sahles bestimmen (und dort erläutert sind). Der Blog dient als Verzeichnis der seit 2008 im deutschsprachigen Raum erfolgten Ausschreibungen für DH-Professuren, ein Anspruch auf Vollständigkeit wird dabei nicht erhoben. DH-Professuren, die besetzt, aber nicht ausgeschrieben wurden, werden nicht aufgeführt. Ein Listeneintrag besteht aus einer fortlaufenden Nummerierung sowie Jahr der Ausschreibung, Ort, Stufe, Denomination, Zuordnung und Ergebnis der Ausschreibung, zum Beispiel:
- 33, 2015, Wien, A1, Digital Humanities, Historisch-kulturwissenschaftliche Fakultät, Andrews
Dies lässt sich lesen als: 2015 wurde an der Historisch-kulturwissenschaftlichen Fakultät der Universität Wien eine unbefristete A1-Professur für „Digital Humanities“ ausgeschrieben und (nach Durchlaufen des Verfahrens, also in der Regel deutlich später) durch Tara Andrews besetzt.
Zwei Angaben sind für die raum-zeitliche Visualisierung über das Jahr der Ausschreibung hinaus besonders wichtig und sollen aus diesem Grund hier noch einmal kontextualisiert werden: Die Kategorie „Ort“ bezeichnet den Sitz der Hochschule, an dem die jeweilige Stelle ausgeschrieben wurde. Handelt es sich um eine Universität, wird auf den Eigennamen verzichtet (z.B.: „Düsseldorf“ statt „Heinrich-Heine-Universität Düsseldorf“). Vorteil davon ist, dass der Eintrag im Falle einer Umbenennung wie zuletzt etwa in Münster („Westfälische Wilhelms-Universität Münster“ zu „Universität Münster“) nicht angepasst werden muss. Fachhochschulen werden durch „FH“ gekennzeichnet. Bei Orten mit mehreren Universitäten erfolgt eine Präzisierung (z.B.: „Berlin (TU)“ für Technische Universität Berlin, „Berlin (HU)“ für Humboldt-Universität zu Berlin und „Berlin (FU)“ für Freie Universität Berlin). In unserer Visualisierung werden die Institutionen unterschieden, aber nicht an unterschiedlichen Orte innerhalb der jeweiligen Stadt visualisiert. In der Kategorie „Stufe“ wird durch „*“ auf eine befristete oder durch „°“ auf eine nebenberufliche Professur verwiesen. Bei dem Element Ergebnis wird durch „offen“ auf eine noch unbesetzte Stelle, durch „-„ auf ein abgebrochenes Verfahren und durch graue Unterlegung auf das Wiederverlassen der Stelle verwiesen. Zeitpunkte und -abläufe beziehen sich demnach auf den Zeitpunkt der Ausschreibung (mit dem Jahr als kleinste verwendete Zeiteinheit) sowie eine mögliche Befristung. Soweit ermittelbar, sind die Informationen zur Dauer der Besetzung einer Professur durch eine Person in den Datensatz aufgenommen worden.
Der DARIAH-DE Geo-Browser ermöglicht die dynamische und statische Darstellung von Daten und deren Visualisierung in einer Korrelation von geografischen Raumverhältnissen zu Zeitpunkten und -abläufen. Mittels der Visualisierung können räumliche Konzentrationen und Trends ersichtlich werden. Zur Visualisierung mittels des Geo-Browsers müssen die Datenstrukturen den Anforderungen des Geo-Browsers angepasst werden. Ein Eintrag des Geo-Browsers besteht aus neun Elementen: Name, Address, Description, Longitude, Latitude, Time Stamp, Time Stamp:begin, Time Stamp:end und GettyID.
- Name besteht aus der Kombination „Universität Ort“ oder „Fachhochschule Ort“. Eine Präzisierung erfolgt nur, wenn sie durch mehrere Universitäten notwendig wird.
- Address besteht aus dem Ortsnamen der Universität oder Hochschule. Für Universitäten oder Hochschulen, die an mehreren Orten lokalisiert sind, verwenden wir den erstgenannten Ort (z.B. Universität Erlangen-Nürnberg hat als Address „Erlangen“). Eine Zuordnung zu mehreren Orten ist im Geo-Browser nicht möglich.
- Description umfasst Stufe, Denomination, Zuordnung und Ergebnis der Ausschreibung nach folgendem Schema: Ergebnis: Denomination (Stufe), Zuordnung.
- Longitude, Latitude und GettyID wurden mit dem „Getty Thesaurus of Geographic Names (TGN)“ (https://www.getty.edu/research/tools/vocabularies/tgn/; Zugriff: 08.07.2024) ermittelt. Mit TGN kann jedem Ort genau ein Längen- und Breitengrad sowie eine eindeutige GettyID (eine Identifikationsnummer) zugeordnet werden. Eine exaktere Lokalisierung ist dem Sinn des Blogs entsprechend nicht vonnöten.
- Timestamp wird freigelassen, da keine exakten Zeitpunkte bestimmt werden müssen.
- Time Stamp:begin erhält als Eintrag das Jahr der Ausschreibung in der Form 20xx-01-01.
- Time Stamp:end haben wir bei unbefristeten Stellen generell auf 2039 gesetzt, den im Geo-Browser (derzeit) spätestmöglichen Zeitpunkt. Bei befristeten Juniorprofessuren verwenden wir das Fristende der jeweiligen Professur. Bei abgebrochenen Ausschreibeverfahren sind time stamp:begin und time stamp:end identisch, wodurch der entsprechende Eintrag in der dynamischen Visualisierung unberücksichtigt bleibt. Im statischen Modus wird der entsprechende Eintrag dargestellt.
Einige konkrete Beispiele aus unserem in dieser Art modifizierten Datensatz vermögen die Details zu verdeutlichen:
- Universität München, München, Schröter: Digitale Literaturwissenschaften (W2* mit TT W2), Department Germanistik, 13.466667, 48.7, 2022-01-01, 2028, 7134068
Dieses Datenelement wird gelesen als: Am Department Germanistik der Ludwig-Maximilians-Universität München wurde 2022 eine (zum Zeitpunkt der Ausschreibung) bis 2028 befristete W2-Professur (mit Tenure Track) für Digitale Literaturwissenschaften ausgeschrieben und durch Julian Schröter besetzt. München besitzt die GettyID 7134068 und (das Stadtzentrum) befindet sich nach TGN bei Längengrad 13.466667 und Breitengrad 48.7.
- Universität Heidelberg, Heidelberg, offen: Papyrologie und Digitale Erforschung antiker Schriftzeugnisse (W3), Heidelberg Center for Digital Humanities (HCDH), 8.916667, 48.316667, 2024-01-01, 2039-12-31, 7166144
Dieses Datenelement wird gelesen als: Am Heidelberg Center for Digital Humanities (HCDH) der Universität Heidelberg wurde 2024 eine unbefristete W3-Professur für Papyrologie und Digitale Erforschung antiker Schriftzeugnisse ausgeschrieben. Die Stelle ist noch unbesetzt. Heidelberg besitzt die GettyID 7166144 und (das Stadtzentrum) befindet sich nach TGN bei Längengrad 8.916667 und Breitengrad 48.3166667.
AbschlussZusammenfassend lässt sich festhalten, dass unsere raumzeitliche Visualisierung der DH-Professuren im deutschsprachigen Raum eindrucksvoll die dynamische Entwicklung und die wachsende Bedeutung der Digital Humanities in der akademischen Landschaft aufzeigt. Diese kartografische Darstellung ermöglicht es, nicht nur die Verteilung und Häufigkeit der Professuren zu analysieren, sondern auch Hotspots oder ‘einsame Helden’ der DH-Entwicklung zu identifizieren. Durch die Integration in den DARIAH-DE Geo-Browser bieten wir Forscherinnen und Forschern, DH-Strukturverantwortlichen, Infrastruktureinrichtungen sowie der interessierten Öffentlichkeit eine neue Perspektive auf die Daten aus dem Blogpost von Patrick Sahle an. Die zunehmende Verbreitung und Etablierung von DH-Professuren zeigt jedenfalls, dass die Digital Humanities eine zentrale Rolle in der Zukunft der Geisteswissenschaften spielen werden.
[1] Wir danken herzlich Vincent Anker (studentische Hilfskraft im Service Center for Digital Humanities (SCDH) der Universität Münster) für seine tatkräftige Unterstützung bei der Aufbereitung der Daten.
11.07.: Online-Vortrag von PD Benjamin Gittel im Rahmen des TCDH-Forschungskolloquiums
Am 11.07.2024 findet der letzte Vortrag im Rahmen des TCDH-Forschungskolloquiums statt:
PD Benjamin Gittel (Trier): „Zuschreibungen und textuelle Korrelate fiktionaler Kritik”
Im Sommersemester 2024 setzen wir unsere Vortragsreihe im Rahmen des TCDH-Forschungskolloquiums wieder fort. Studierende, Mitarbeitende und Fellows des TCDH geben ebenso wie externe Kolleg:innen und Kooperationspartner spannende Einblicke in ihre Arbeit aus ganz unterschiedlichen Feldern der Digital Humanities: der Computational Literary Studies, der digitalen Lexikographie und der digitalen Pragmatik, der digitalen Theaterforschung und der digitalen Edition.
Das Forschungskolloquium findet von 16 bis 18 Uhr (c.t.) via Zoom statt: https://uni-trier.zoom-x.de/j/67058779378?pwd=UFZ4WjBwNWVEaWFLRzh0aWszWkRudz09
Sie sind herzlich eingeladen, teilzunehmen und mitzudiskutieren!
{kind=link}
ECHOES24 Conference: Mit dem digitalen Echolot zu den Untiefen musikwissenschaftlicher Erkenntnis
Das Forschungsprojekt „Echoes from the Past: Unveiling a Lost Soundscape with Digital Analysis” (2023-2026), angesiedelt an der Universidade NOVA de Lisboa, untersucht die Musik des Mittelalters mit digitalen Methoden. Auf interdisziplinärem Terrain verspricht es somit neue Erkenntnisse für die historische Musikforschung und Musiktheorie, die Digital Humanities (Computational Musicology) und das Music Information Retrieval (MIR) gleichermaßen.
Teil des Projekts war die einmalig stattfindende Konferenz „ECHOES24“, auf der ich Ende Juni erste Ergebnisse meines Promotionsprojekts vorstellen durfte. Sie führte weltweit führende Wissenschaftler:innen des Forschungsbereichs, ebenso wie Promovierende, Early Career Scholars und Professor:innen in Lissabon zusammen, um über „Digital Technologies Applied to Music Research: Methodologies, Projects and Challenges“ zu diskutieren.
In meiner Promotion beschäftige ich mich im Rahmen einer digitalen Korpusstudie mit Polymetrik und metrischen Irregularitäten in den Kompositionen Hugo Distlers, Béla Bartóks und Paul Hindemiths. (Polymetrik nennt man – ganz allgemein – gleichzeitig auftretende, unterschiedliche Taktarten, siehe Abb. 1.) Darauf aufbauend möchte ich ein eigenes Bayessches Modell für Polymetrik entwickeln. Solche metrisch komplexen Strukturen werden in der aktuellen Forschung zur computergestützten Musikwissenschaft noch weitgehend außen vor gelassen, unter anderem da deren Modellierung und computergestützte Analyse bestehende Ansätze und Codierungsformate an ihre Grenzen führt. Mit meinem Forschungsvorhaben möchte ich diese Lücke schließen und mittels einer ergebnisoffenen Grundlagenforschung einen signifikanten Beitrag zur Analyse komplexer Musik, insbesondere des 20. Jahrhunderts, leisten. Daher interessierten mich explizit die auf der Konferenz behandelten Themenbereiche „Key challenges in applying digital technologies to music research” sowie „Music encoding”.
Abb. 1: Beginn von Hugo Distlers Motette „O Heiland, reiß die Himmel auf“ aus Der Jahrkreis op. 5 (1933). Jede Stimme wird in ihrer je eigenen Metrik ausgestaltet; die Taktarten wechseln sehr häufig.[1]{kind=link}
Herausforderungen bei der Codierung von Polymetrik
Für meine Promotion und beginnende wissenschaftliche Karriere stellte diese Konferenz ein wichtiges Sprungbrett dar. Dort konnte ich zum ersten Mal mein eigenes Forschungsprojekt in einem öffentlichen Vortrag international präsentieren. Explizit stellte ich die Möglichkeiten und Grenzen der Codierung von Polymetrik in verschiedenen Musikcodierungsformaten vor (Folien; Videomitschnitt, leider ohne Ton). Zu meiner Freude war mein Vortrag sehr gut besucht und das Publikum aufmerksam interessiert. Mein Befund, dass Polymetrik in den bestehenden Formaten MusicXML, MEI und Humdrum (noch) nicht originalgetreu codiert werden kann, überraschte die Anwesenden. An den drei Konferenztagen konnte ich mich darüber in vielen Gesprächen austauschen – deshalb wurden gerade die Kaffeepausen zu den wichtigsten Zeiten für mich. Wir haben auch schon gemeinsam erste Lösungsansätze diskutiert, die aufgrund des starken Alte-Musik-Fokus der Konferenz neben dem modernen Westlichen Notationssystem dankenswerterweise auch die Mensuralnotation einschlossen – ein vielversprechender Ansatz!
Abb. 2: Deckblatt meines Konferenzvortrags bei der ECHOES24 Abb. 3: Interessiert-lockere Atmosphäre während des Vortrags{kind=link}
Musikforschung zwischen Gaga und Bioinformatik
Insgesamt hörte ich in den drei Tagen 15 Vorträge sowie zwei Keynotes, und besuchte zwei Workshops: in toto eine Tour d’Horizon durch die digitale Musikforschung. In Parallel Sessions fanden gleichzeitig Vorträge in den Bereichen „Digital Early Music“ und „Digital Musicology“ statt. Hier eine Auswahl:
Tillman Weyde (City, University of London) stellte kollaborative Tools in der Jazz-Forschung vor, die synergetisch Methoden des Music Information Retrieval (MIR) und des maschinellen Lernens kombinieren. Insbesondere besprach er seine JazzDAP Studien, die auf den bekannten Arbeiten zur Dig That Lick Database sowie dem Jazzomat Research Project aufbauen.
Das Warschauer Fryderyk-Chopin-Institut um Marcin Konik, Jacek Iwaszko und Craig Sapp stellte das beeindruckende Projekt „Polish Music Heritage in Open Access“ (siehe Polish Scores) vor: ein Online-Repositorium polnischer Musik aus sechs Jahrhunderten, das rund 25.000 Manuskripte und Partituren mit insgesamt einer halben Million Seiten Musik umfasst. Die digitalen Editionen enthalten Codierungen im Humdrum-Format, die mittels IIIF-Koordinaten mit den originalen Partiturseiten verbunden sind.
Andreas Waczkats (Göttingen) forscht zur Rekonstruktion des Klangs einer Londoner Orgel, auf der Georg Friedrich Händel einst spielte. Dem Klangideal nähert sich Waczkat mithilfe des Tools „SOUND“ (FU Berlin), das 3D Sound-Daten verwendet, sowie der VR-Anwendung „Virtual Acoustics“ (RWTH Aachen).
Maria Navarro Cáceres (Salamanca) untersuchte in 20.000 irischen und spanischen volkstümlichen Melodien die Verwendung verschiedener Kirchenmodi. Interessant: Vor allem im spanischen Raum ist Phrygisch sehr beliebt!
Tim Eipert (Würzburg) und Francisco Camas (Madrid) verwendeten in Ihrer Forschung zu mittelalterlichen Tropen unabhängig voneinander bioinformatische Methoden der Phylogenese, um die Provenienz verschiedener Gesänge mit ihren musikalischen Stilen abzugleichen. Daraus ließ sich eine „Stammesgeschichte“ verschiedener mittelalterlicher Gesänge ableiten. Insbesondere diese beiden Forschungsprojekte stießen auf großes Interesse, da hier sowohl die Integration in die historische Musikforschung als auch der erwartete Erkenntnisgewinn sehr vielversprechend ist.
Ganz allgemein war der Wunsch nach Interdisziplinarität im Plenum deutlich spürbar. In diesem Sinne warb Cory McKay (Marianopolis College) für mehr Kommunikation und Offenheit bei Kooperationen zwischen der Musikwissenschaft und der Informatik bzw. dem MIR. Seinem Vortrag stellte er die methodologisch entscheidende Frage voran, „how to make musicological sense out of computer data“. Neben der gründlichen Vor- und Aufbereitung musikalischer Daten, um Biases zu vermeiden, trügen vor allem Visualisierungen zum Verständnis bei.
Adam Knight Gilbert (USC, Los Angeles) entwickelte gemeinsam mit Andrew Goldman (Indiana University) den GaGA-(Gilbert-and-Goldman)-Algorithm, mit dem sie Symmetrien in Kontrapunktwerken des 15. Jahrhunderts identifizieren können. Auf diese Weise untersuchten sie verschiedene Formen musikalischer Palindrome („Inversodrome“, „Crabindrome“) in Chansons von Gilles Binchois sowie in Messen und Motetten Johannes Ockeghems. Sie stellten die Frage in den Raum, inwieweit solche Symmetrien kompositorisches Spiel oder kontrapunktisches Derivat sind.
Keynotes: Schon viel erreicht und noch mehr zu tun
Besonders beeindruckend war die abendliche Keynote von Ichiro Fujinaga (McGill University), der seit 40 Jahren Pionierarbeit auf dem Gebiet der Optical Music Recognition (OMR) leistet. Humorvoll veranschaulichte er die Errungenschaften in diesem Bereich und ermutigte, die aktuellen Herausforderungen anzugehen. Er warb insbesondere für das Konzept der „Mechagogy“, dem Machine Teaching als Fähigkeit, Computer und Künstliche Intelligenzen richtig zu „erziehen“ und somit leistungsstärker und lösungsorientierter zu machen. An dieses Konzept konnten auch die Kunstsoziologen Denise Petzold und Jorge Diaz Granados (Maastricht) anschließen, die zur Diskussion über die Frage anregten, ob digitale Technologien als Musikinstrumente angesehen werden sollten.
In der zweiten Keynote mit dem Titel „Sustaining Digital Musicology“ plädierte Jennifer Bain (Dalhousie University) für mehr Kooperation innerhalb der Musikforschung, um Forschungsdaten langfristig erhalten zu können. Mit erschreckenden Zahlen aus den vergangenen drei Jahren warnte sie vor Datenverlust durch Cyberattacken. Das Rechenzentrum der Dalhousie University etwa (mit ihren 20.000 Studierenden) blockiert täglich 800.000 Spam-Mails. Die British Library arbeitet seit einem verheerenden Hacker-Angriff vergangenen Oktober immer noch an der Wiederherstellung wertvoller Daten. Leider seien es häufig DH-Projekte, die den Weak Link ins Unisystem darstellen, da ältere Online-Projekte oftmals keine Updates mehr durchlaufen. Der Nachhaltigkeit solcher Projekte abträglich seien zudem schlechte Dokumentation und ein erschwerter Zugang zu Fördermitteln. Was also tun? Zielführend seien gemeinsame, interdisziplinäre Projekte, die auf bestehenden Tools aufbauen, und vor allem gemeinsame Metadaten-Standards innerhalb der Community. Jennifer Bain schloss zuversichtlich: „The future of Digital Musicology looks bright. Let us be more intentional.”
Ein solches verheißungsvoll-intentionales Projekt stellte Ichiro Fujinaga abschließend in einem interaktiven Workshop vor: LinkedMusic. Dessen Ziel ist es, von einer Website aus in verschiedenen Musikdatenbanken suchen zu können, und zwar ausdrücklich auch in anderen Sprachen als Englisch. Die Herausforderung dabei: Die 14 verbundenen Datenbanken haben 14 inkompatible Datenbankstrukturen. Integrierte Bestandteile von LinkedMusic sind u. a. Linked Open Data, Semantic Web (für Interoperability und Data Integration), der RDF-Standard, die SPARQL Language sowie OpenRefine zur Bereinigung und Konvertierung von Daten.
Abb. 4: 14 Datenbanken in LinkedMusic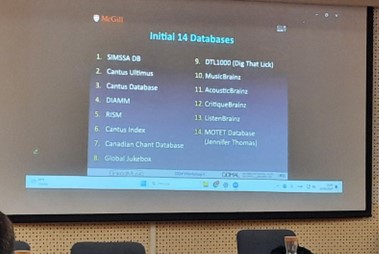{kind=link}
Quintessenz
{kind=link}
Was nehme ich von der Konferenz mit? Einen vollen Kopf, eine Liste an Mailadressen, viele offene Google-Tabs und noch mehr offene Fragen, etliche Forschungsideen und sogar schon Angebote für Forschungsaufenthalte an der Stanford University und der McGill University. In jedem Fall waren meine Erlebnisse auf der ECHOES24 überaus positiv, vor allem geprägt durch das angenehme Konferenzklima (sowohl zwischenmenschlich als auch meteorologisch). Dazu beigetragen haben allem voran das ehrliche Interesse der Teilnehmenden und die wertschätzende Feedback-Kultur, die in dieser Form insbesondere für Promovierende wünschenswert ist.
Abb. 5: Ein Kalauer am Ende des Vortrags leitete zur Diskussion über.{kind=link}
Der Autor dankt dem DHd-Verband für die Ermöglichung der Konferenzteilnahme durch das Reisekostenstipendium für DH-nahe Tagungen (Sommer 2024).
Kontakt: lucas.hofmann@uni-wuerzburg.de
[1] Hugo Distler, „O Heiland, reiß die Himmel auf“, in: Der Jahrkreis op. 5, Kassel 1933, S. 8, Beginn.
DARIAH Annual Event 2025 in Göttingen!
While the DARIAH Annual Event 2024 in Lisbon is still fresh in our minds, we are already looking forward to next year’s meeting: The DARIAH Annual Event 2025 will be held from June 17-20 in Göttingen, hosted by the Göttingen State and University Library (SUB Göttingen), with the main conference days on June 18–20 (Wednesday to Friday).
Additionally, the annual plenary of the NFDI consortium Text+ will be held in Göttingen on June 16–17. Text+, a consortium focused on text and language-related research data, addresses disciplines that are also of significant interest to DARIAH. Holding these two events back to back is both logical and mutually beneficial. It allows for an exchange between numerous related interest groups and disciplines. DARIAH covers the entire humanities, arts, and cultural sciences, while Text+ represents the text- and language-based research communities and the former CLARIN-D and DARIAH-DE leading institutions.
{kind=link}
Germany is a founding member of the ERIC DARIAH-EU with its leading institution SUB Göttingen since 2014. Göttingen played a pivotal role in all project phases of the German DARIAH node, DARIAH-DE, from 2011 to 2019, and continued to support the DARIAH-DE Operations Cooperation until 2021. Currently, DARIAH-DE is led by the SUB Göttingen (DARIAH-DE Coordination Office), the Max Weber Foundation (National Coordinator) and the GWDG Göttingen (technical lead). All three institutions also participate in Text+ and further NFDI consortia as well as the Association for Research Infrastructures in the Humanities and Cultural Studies.
By locating the DARIAH Annual Event 2025 in Göttingen, it has therefore succeeded in bringing together national and NFDI perspectives with European ones in a joint event. This enables joint work on research infrastructures, data literacy, open science, and the implementation of the FAIR principles. Thus, it is a fittinge choice for the DARIAH Annual Event 2025 to take place in Göttingen, where history and present, national and international cooperation, content and technical leadership, Germany and Europe converge.
Until then, mark your calendars and save the date!
Abstracts schreiben für die DHd: Tipps und Tricks
Das Verfassen von Konferenz-Abstracts ist eine zentrale Tätigkeit im akademischen Alltag. Dennoch gibt es kaum Materialien, die Anfänger:innen hierbei unterstützen. Ich habe viel dadurch gelernt, selbst als Gutachterin tätig zu sein. Doch die Gutachter:innentätigkeit steht Early Career Scholars im Normalfall noch nicht offen. Deshalb möchte ich einige Tipps aus meiner eigenen Erfahrung als Reviewerin teilen, die beim Verfassen eines Abstracts für die DHd-Konferenz 2025 in Bielefeld hilfreich sein könnten.
[Dieser Beitrag ist eine deutschsprachige und adaptierte Version des folgenden Blogposts, der noch mehr konkrete Kritikpunkte aus meiner Reviewer:innentätigkeit enthält: How to write a (Digital Humanities) abstract? Lessons Learned from Reviewing, in: The LaTeX Ninja Blog ]
Die Abstract TriasZunächst möchte ich auf die nützlichen Tipps von Karen Kelsky hinweisen, die die formelhafte Struktur von Abstracts betonen:
- Thema und Relevanz: Beginnen Sie mit einem breit diskutierten Thema. Dabei handelt es sich noch nicht um das eigentliche Thema des Abstracts, sondern ein größeres Thema oder einen Diskurs, dem Sie sich angehörig fühlen. Erklären Sie das Thema und seine Relevanz, sodass auch Personen, die nicht in diesem Bereich arbeiten, es verstehen können. Die Relevanz muss also recht allgemein sein.
- Forschungslücke oder Problem: Dann identifizieren Sie eine Lücke in der Literatur oder ein Problem in der aktuellen Forschung. Dies kann am Anfang der Karriere schwierig sein, da Sie noch keinen so guten Überblick über die Forschung haben. Hierbei können Mentor:innen oder Kolleg:innen helfen. Geben Sie an, welche Materialien Sie betrachten und mit welchen Methoden Sie diese analysieren.
- Lösungsansatz bzw. Held:innennarrativ: Beschreiben Sie, wie Ihr eigenes Projekt oder Ihr Vorschlag diese Lücke oder dieses Problem adressiert.
Zur Veranschaulichung ein Beispiel: „Digitale Editionen sind zentrale Medien, um hochqualitative Primärtexte zur Verfügung zu stellen, doch das Feld ist weiterhin vom traditionellen Kanon dominiert (Hall 2019). Dadurch reproduziert sich dieser. Das Data Feminsim Manifest (D’Ignazio/Klein 2020) bietet Strategien, um hier Abhilfe zu schaffen. Dieser Beitrag…“ Falls Sie sich für Data Feminism interessieren, kommen Sie doch mal beim Jour Fixe der AG Empowerment vorbei!
Was zeichnet einen guten Abstract aus?Quinn Dombrowski hat ebenfalls Tipps zum Verfassen von Abstracts für die ADHO-Jahrestagungen zusammengestellt, die genauer darauf eingehen, wodurch eine gute Einreichung charakterisiert ist:
Verorten Sie die eigene Arbeit innerhalb bestehender Diskurse und versuchen Sie klarzustellen, was an Ihrer Arbeit neu ist oder was sie dem Stand der Forschung hinzufügt, sei es eine neue Perspektive, neue Daten oder eine neue Methode. Dabei sollte die Methodologie so konkret wie möglich beschrieben werden, ohne jedoch in übermäßige technische Details abzuschweifen, da Sie dadurch vermutlich über die Zeichengrenze kommen würden.
Stellen Sie sicher, dass Ihre Einreichung lesbar und gut strukturiert ist und den Stylesheet Guidelines zur Einreichung entspricht. Es ist ebenfalls wichtig, dass das Abstract der Einreichungskategorie bzw. dem gewählten Format entspricht. Zum Beispiel werden bei vielen Tagungen für Long Papers andere Arten von Einreichungen erwartet als für Poster, Short Papers oder Lightning Talks. Bei DHd-Tagungen gibt es Vorträge, Vorträge im Doctoral Consortium, Panels, Poster und Workshops. Lesen Sie den Call for Papers genau und passen Sie sich möglichst gut in die entsprechende Kategorie ein.
Anfangs fällt es schwer, die eigene Forschung so zu erklären, dass deren Fokus und Relevanz auch für Außenstehende ersichtlich ist. Man steckt inhaltlich so tief in einer Niesche, dass man nicht mehr erkennt, welche Begriffe beispielsweise nicht allgemein verständlich sind oder sich wundert, warum anderen Zeitgenoss:innen nicht sofort klar ist, warum die eigene Forschung wichtig ist. Ziehen Sie im Zweifelsfall Freunde und Kolleg:innen zurate und verbessern den Beitrag, bis er leichter verständlich ist und die zentralen Punkte nachvollziehbar herausstellt.
Typische Fehler beim Schreiben von Konferenzabstracts und wie man sie vermeidetAls Reviewerin habe ich im Laufe der Zeit einige wichtige Lektionen darüber gelernt, wie man gute Abstracts schreibt. Es sind oft dieselben Fehler, die immer wieder auftauchen – und ja, auch ich mache diese Fehler. Es kann hilfreich sein, diese typischen Stolpersteine zu kennen und als Checkliste zu nutzen, um die Chancen zu erhöhen, dass die eigene Einreichung angenommen wird.
Fehler 1: Falsche Annahmen über das Vorwissen der Reviewer:innenEin häufiger Fehler ist die Annahme, dass Reviewerinnen sich extrem gut mit dem eigenen Thema auskennen. Tatsächlich kennen sich im Normalfall die Autor:innen selbst am besten mit ihrem eigenen Thema aus. Hier gilt es nun, dieses große Wissen für andere herunterzubrechen, die zwar im selben Feld tätig sind und denen dessen größere Diskurse bekannt sind, die aber selbst zu einem anderen Thema forschen.
Anfänger:innen tendieren hier meist entweder dazu, nicht genug zu erklären oder Bereiche, in denen sie selbst unsicher sind, zu ausführlich zu behandeln (auch wenn diese vielleicht für langjährige DHd-Teilnehmende zum Allgemeinwissen gehören). Zu viele Erklärungen von Grundlagen können daher inkompetent wirken, während fehlende Erklärungen von nicht selbstverständlichen Dingen zu Missverständnissen führen. Diese Balance zu finden ist für Neulinge nicht gerade trivial, aber mit Erfahrung wird das einfacher!
Fehler 2: Ungleichgewicht zwischen technischen Details und geisteswissenschaftlicher RelevanzBei allgemeinen Digital Humanities Konferenzen wie der DHd ist es wichtig, die richtige Balance zwischen technischen Erklärungen und der Relevanz für die Geisteswissenschaften zu finden. Ein Abstract sollte technisch nicht zu detailliert, aber auch nicht zu vage sein.
Vage Einreichungen machen es Reviewer:innen schwer, diese zu bewerten, was zu Punktabzügen führt. Bleiben Sie konkret, d.h. arbeiten mit konkreten Beispielen, die Sie nachvollziehbar erklären, statt allgemeine Behauptungen zu machen. Meine Studierenden machen dies sehr häufig, weil Ihnen Verallgemeinerungen (z.B. durch Nominalisierungen und Passivkonstruktionen) vermutlich gebildet und wissenschaftlich vorkommen. Doch Expert:innen durchschauen leere Worthülsen recht schnell, also bleiben Sie konkret und vermeiden Sie Verallgemeinerungen. Bedenken Sie auch, dass AI-Textgenerierung oft genau diese Fehler macht und liebend gern Konkretes verallgemeinert. Hier ist Vorsicht geboten!
Fehler 3: Fehlende Relevanz und KontextualisierungVergessen Sie nicht, die Relevanz des eigenen Themas zu erklären! Warum ist es wichtig, sich damit zu beschäftigen? Was bringt es, und warum sollte jemand Ihren Vortrag besuchen, auch wenn die Person sich selbst nicht mit Ihrem Detailthema befasst? Diese Außenperspektive hilft, die Bedeutung des eigenen Projekts zu kommunizieren.
Fehler 4: Unbelegte Behauptungen und fehlende LiteraturAuch wenn Anforderungen für Abstracts in diesem Punkt variieren, ist es bei den DHd-Abstracts wichtig, eine Bibliografie beizufügen. Stellen Sie sicher, dass relevante Literatur zitiert ist und Sie Ihre Behauptungen mit Sekundärliteratur belegen.
Fehler 5: Verwendung von Fachbegriffen ohne ErklärungUnerklärte Fachbegriffe oder nicht aufgelöste Akronyme können ebenfalls problematisch sein. Jedes Feld hat seine Fachbegriffe, aber es ist oft für Neulinge unklar, welche vorausgesetzt werden können und welche erklärt werden müssen. Es ist daher sinnvoll, eventuell nicht allgemein geläufige Fachbegriffe zu erklären oder Abkürzungen beim ersten Vorkommen auszuschreiben. Zu ausführliche Definitionen allgemein bekannter Begriffe werden allerdings von Expert:innen auch nicht gern gelesen, daher bietet es sich an, eine den Textfluss nicht weiter störende Kurzdefinition einzuschieben. Hier ein Beispiel: „Fibeln, antike Gewandnadeln, sind eine wichtige Fundkategorie in der Archäologie.“ Unterschätzen Sie nicht die Wichtigkeit solcher Erklärungen. Auf der DHd-Tagungen treffen sich Menschen, die zwar ihre Digital Humanities Methoden gemeinsam haben, die aber aus der unterschiedlichen fachlichen Hintergründen kommen können. Es gibt keine Garantie, dass Ihr Abstract von einer Person begutachtet wird, die aus Ihrer eigenen Fachdisziplin stammt. Bedenken Sie dies beim Formulieren Ihres Textes.
Feedback einholenEine gute Strategie ist es, das Abstract rechtzeitig fertigzustellen und es vor der Einreichung einer Person zu zeigen, die nicht so tief in Ihrem Thema drinsteckt wie Sie selbst. Feedback von außen hilft, Unklarheiten zu identifizieren und die Verständlichkeit zu verbessern.
Ich habe dies selbst lernen müssen, da ich mich inhaltlich mit Alchemieforschung befasse. Da ich dadurch immer viel mehr über das Thema wusste als die meisten anderen, denen es lediglich aus der Populärkultur geläufig ist, und sich außer mir kaum jemand in den DH damit befasst, muss ich den Kontext immer so erklären, dass er für Außenstehende verständlich ist. Ohne diese Erklärungen greifen Leser:innen auf eigenen Vorurteile zurück, was bei mir initial zu einigen Ablehnungen geführt hat, die auf inhaltlich schlichtweg falschen Kritikpunkten beruhten. Meist reicht es aus, einfach anfangs den aktuellen Forschungsstand zur Alchemie zu zitieren und deren Rolle in der Wissenschaftsgeschichte kurz zu erklären. Mittlerweile weiß ich, wie ich das kommuniziere und hatte auch seither keine Probleme mehr.
FazitDas Schreiben erfolgreicher Abstracts erfordert Übung und Feedback. Nutzen Sie die oben genannten Strategien und Tipps, um Ihre Abstracts zu verbessern und Ihre Forschung effektiv zu präsentieren. Viel Erfolg bei Ihren Einreichungen!
Reminder: Einladung zum DHd Community Forum am 05.07.2024
Liebe Mitglieder des DHd-Verbandes und Interessierte,
für unsere interdisziplinäre Community ist ein offener Austausch von großer Bedeutung. Während die jährliche Mitgliederversammlung bereits eine wichtige Rolle für unsere communityinterne Verständigung übernimmt, unterstützen wir als Vorstand weitere partizipative Angebote. Alle Mitglieder und Interessierte sind herzlich eingeladen, sich an den Diskussionen zu beteiligen sowie Themenvorschläge (info@dig-hum.de) einzureichen.
Das nächste virtuelle Community Forum findet am Freitag, dem 5. Juli 2024 von 14–15 Uhr statt.
Gegenstand des Community Forums ist zum einen der im Dezember 2023 veröffentlichte Code of Conduct der Alliance of Digital Humanities Organizations (ADHO). Wir möchten das Community Forum nutzen, um mit Ihnen über mögliche Änderungsbedarfe für den DHd-Verband zu sprechen. Zum anderen bietet das Community Forum Gelegenheit, das Thema „Angreifbarkeit & Selbstschutz von Wissenschaftler*innen im DHd-Verband“ zu diskutieren. Weitere Themen können wie immer zu Beginn des Community Forums vorgeschlagen werden.
Für das Community Forum werden wir das Videokonferenztool BigBlueButton nutzen. Wir möchten Sie bitten, sich mit vollständigem Namen anzumelden.
https://webroom.hrz.tu-chemnitz.de/gl/rab-rg7-psq-qcn
Wir freuen uns auf den Austausch mit Ihnen!
Mit freundlichen Grüßen
Rabea Kleymann (als Koordinatorin des Community Forums)
SCDH Münster: E13-Stelle Korpuslinguistik/NLP ausgeschrieben
{kind=link}
An english version of the job posting can be found here: https://stellen.uni-muenster.de/jobposting/dd360cc79bc3535d342f9e5b618d32aced4af1840?
43.000 Studierende, 8.000 Beschäftigte in Lehre, Forschung und Verwaltung, die gemeinsam Zukunftsperspektiven gestalten – das ist die Universität Münster. Eingebettet in die Atmosphäre der Stadt Münster mit ihrer hohen Lebensqualität zieht sie mit ihrem vielfältigen Forschungsprofil und attraktiven Lehrangeboten Studierende und Wissenschaftlerinnen und Wissenschaftler aus dem In- und Ausland an.
Das an der ULB Münster angesiedelte Service Center for Digital Humanities (SCDH) unterstützt die Forschenden der Universität Münster im Bereich Digital Humanities (DH) mit zahlreichen Services. Im SCDH ist zur Begleitung des Projekts „PRODATPHIL: Science and Logic – eine programmierbare Datensammlung und ein digitaler Überblick zur Logik und Wissenschaftstheorie im 19. und frühen 20. Jahrhundert“ (Leitung Dr. Stefan Heßbrüggen-Walter) zum nächstmöglichen Zeitpunkt eine Stelle als
Wissenschaftliche*r Mitarbeiter*in im Kontext DH mit dem Schwerpunkt Korpuslinguistik (E 13 TV-L)
zu besetzen. Angeboten wird eine zunächst bis 30.06.2027 befristete Vollzeitstelle (100 %) mit der Option auf Verlängerung bzw. Entfristung.
Ihre Aufgaben:- Analyse (multilingualer) textueller Daten (Korpora) mit computerlinguistischen Methoden (z.B. NER, relative Häufigkeiten, Streuung, Kollokation, Dimensionsreduktion (PCA), Wordembeddings, automatische Anreicherung)
- Evaluation und Einrichtung von Datenbanken
- Data Cleansing und Normalisierung
- Konzeption und Entwicklung von visuellen und statistischen Analysemethoden
- Dokumentation von Datenmodellen und Entwicklungen
Wir suchen eine engagierte Persönlichkeit mit eigenverantwortlichem, lösungsorientiertem Arbeitsstil, sehr guten konzeptionellen Fähigkeiten und ausgeprägter Teamfähigkeit. Sie zeichnen sich darüber hinaus durch Flexibilität sowie gute Kommunikationsfähigkeit aus und erfüllen folgendes Profil:
- einschlägiges Hochschulstudium auf Masterniveau (M.Sc. oder Diplom) der Informatik mit nachgewiesenem Bezug zu den (Digital) Humanities (Zeugnisse/Zertifikate) bzw. einschlägiges Hochschulstudium einer Geisteswissenschaft auf Masterniveau (M.A. oder Magister) aus einem im CDH der Universität Münster repräsentierten Fachbereiche (Ev. Theologie, Kath. Theologie, Erziehungs- und Sozialwissenschaften, Geschichte/Philosophie und Philologie) mit nachgewiesenen Informatikkenntnissen (Zeugnisse/Zertifikate).
- nachgewiesene Erfahrungen in einer Programmiersprache und einschlägigen Libraries oder Softwaresystemen: X-Technologien (z.B. XSLT, saxon), Python (z.B. scrapy, spacy), Javascript (z.B. jsonld.js) (Zeugnisse/Zertifikate)
- ein ausgeprägtes Vermögen zur Analyse und Abstraktion
- Bereitschaft zur Einarbeitung in vielfältige geisteswissenschaftliche Fachdomänen
- Kommunikationsgeschick zur Darstellung von Methoden des Natural Language Processing und zur Überbrückung von Fachjargons
- nachgewiesene Erfahrungen in der eigenverantwortlichen Planung und Durchführung oben genannter Aufgaben (Zeugnisse/Zertifikate)
- nachgewiesener Bezug zu den Digital Humanities (Zeugnisse/Zertifikate)
- Gute Deutsch- und Englischkenntnisse (Niveau B1) bzw. die Bereitschaft, sich diese im Laufe des ersten Jahres der Beschäftigung anzueignen
Darüber hinaus wünschenswert sind:
- Kenntnisse in Optical Character Recognition (OCR) – Kenntnisse im digitalen Edieren (TEI)
- Kenntnisse in Semantic-Web-Technologien (z.B. SPARQL) und Ontologien (z.B: FRBRoo)
- Erfahrung mit Datacleansing-Tools (z.B. openRefine) und -Methoden (z.B. reguläre Ausdrücke) –
- Bereitschaft zur Einarbeitung in LLM-basierte Methoden zu diesen Zwecken
- Wertschätzung, Verbindlichkeit, Offenheit und Respekt – das sind Werte, die uns wichtig sind.
- Mit einer großen Anzahl an unterschiedlichsten Arbeitszeitmodellen ermöglichen wir Ihnen flexibles Arbeiten – auch von Zuhause aus.
- Ob Pflege oder Kinderbetreuung – unser Servicebüro Familie bietet Ihnen konkrete Unterstützungsangebote, damit Sie Privates und Berufliches unter einen Hut bekommen.
- Ihre individuelle, passgenaue Fort- und Weiterbildung ist uns als Bildungseinrichtung nicht nur wichtig, sondern eine Herzensangelegenheit.
- Von Aikido bis Zumba – unsere Sport- und Gesundheitsangebote von A – Z sorgen für Ihre Work-Life-Balance.
- Sie profitieren von zahlreichen Benefits des öffentlichen Dienstes wie z. B. einer attraktiven betrieblichen Altersvorsorge (VBL), einer Jahressonderzahlung und einem Arbeitsplatz, der kaum von wirtschaftlichen Schwankungen abhängig ist.
Die Universität Münster setzt sich für Chancengerechtigkeit und Vielfalt ein. Wir begrüßen alle Bewerbungen unabhängig von Geschlecht, Nationalität, ethnischer oder sozialer Herkunft, der Religion oder Weltanschauung, Beeinträchtigung, Alter sowie sexueller Orientierung oder Identität. Eine familiengerechte Gestaltung der Arbeitsbedingungen ist uns ein selbstverständliches Anliegen. Eine Stellenbesetzung in Teilzeit ist grundsätzlich möglich.
Bewerbungen von Frauen sind ausdrücklich erwünscht. Frauen werden bei gleicher Eignung, Befähigung, und fachlicher Leistung bevorzugt berücksichtigt, sofern nicht in der Person eines Mitbewerbers liegende Gründe überwiegen.
Bei Fragen vorab kontaktieren Sie gerne Herrn Dr. Jan Horstmann (0251-83-25297, jan.horstmann@uni-muenster.de)
Haben wir Ihr Interesse geweckt
Dann freuen wir uns auf Ihre aussagekräftige und vollständige Bewerbung. Senden Sie ihre Bewerbung ausschließlich per E-Mail unter AZ 2024-07 in deutscher oder englischer Sprache und in einer PDF-Datei von maximal 25 MB Größe bis zum 19.07.2024 an: bewerbung.ulb@uni-muenster.de
Internet http://www.ulb.uni-muenster.de
Ausschreibungskennziffer bei Rückfragen: 2024_06_09
(Diese Stellenausschreibung auf den Seiten der Uni Münster: https://stellen.uni-muenster.de/jobposting/87bb75f54cab89d5958cd486ed1856b931e65ff90?ref=homepage)
Community statt Glaskugel: Euer Feedback zur Zukunft des digitalen Publizierens
von Patrick Dinger, Jan Horstmann, Caroline Jansky, Thomas Jurczyk, Timo Steyer (AG Digitales Publizieren)
Die UmfrageAnlässlich ihres zehnjährigen Bestehens wagte die DHd-Arbeitsgruppe Digitales Publizieren auf der DHd2024 in Passau einen Blick in die Zukunft: Ein interaktives Poster (Dinger et al. 2024a) im Rahmen der DHd2024 präsentierte – neben einem Rückblick auf die wichtigsten Meilensteine der AG-Arbeit seit 2014 – fünf Thesen zur Zukunft des (digitalen) Publizierens, die innerhalb der Community zur Diskussion gestellt wurden. Mit Hilfe einer interaktiven Onlineumfrage konnte vor Ort hinsichtlich der persönlichen Einstellung zu den Thesen und der Wahrscheinlichkeit ihrer Realisierung abgestimmt werden.
Für die Umsetzung der Umfrage haben wir das deutschsprachige Online-Tool Particify genutzt. Es ermöglicht eine niedrigschwellige Teilnahme, z. B. indem die persönliche Einstellung zu den Thesen direkt mit einem Emoji ausgedrückt wird. Die Exportoptionen der Daten bei Particify erlauben allerdings keine Korrelationsanalyse, ob etwa die ablehnende Haltung eines Teilnehmenden gegenüber einer bestimmten These auch mit einer geringer eingeschätzten Wahrscheinlichkeit der Realisierung dieser These einhergeht.
Nachdem die Rückmeldungen auf die Umfrage während der Konferenz eher verhalten waren – angesichts von insgesamt 64 Postern nicht verwunderlich – nutzten wir die Möglichkeit, im Anschluss über die DHd-Mailingliste sowie die Mailingliste der AG Digitales Publizieren noch einmal gezielt für die Teilnahme an der Umfrage zu werben: Verschickt wurden die Aufrufe am 08.03.2024, die Umfrage wurde wie angekündigt am 23.04.2024 geschlossen und ausgewertet. In diesem Zeitraum nahmen 114 Personen an der Umfrage teil, von denen 101 Personen den Fragebogen vollständig beantwortet haben. Mit der Veröffentlichung des Umfragelinks über die DHd-Mailingliste und die AG-Liste lässt sich der Kreis der Teilnehmenden auf die deutschsprachige DH-Community eingrenzen, wobei es sich dabei um Personen mit unterschiedlich großem Interesse an dem Thema und divergierenden Erfahrungen im Bereich des digitalen Publizierens handeln dürfte. Vor diesem Hintergrund sind die Umfrageergebnisse zwar nicht repräsentativ, erlauben aber dennoch wichtige Einsichten. Allen Teilnehmenden der Umfrage möchten wir ganz herzlich danken – das große Interesse und die zahlreichen Rückmeldungen bestärken uns in der AG-Arbeit und liefern wichtige Hinweise zu den drängendsten Fragen und Anliegen zum digitalen Publizieren in der Community. Diesen Blogbeitrag nutzen wir dazu, die Ergebnisse der Umfrage, erste Interpretationsansätze und die daraus abgeleiteten Handlungsempfehlungen für die Arbeit der AG vorzustellen. Wir möchten den Beitrag explizit zur Diskussion stellen und freuen uns über Ergänzungen, Kommentare, Kritik und Feedback.
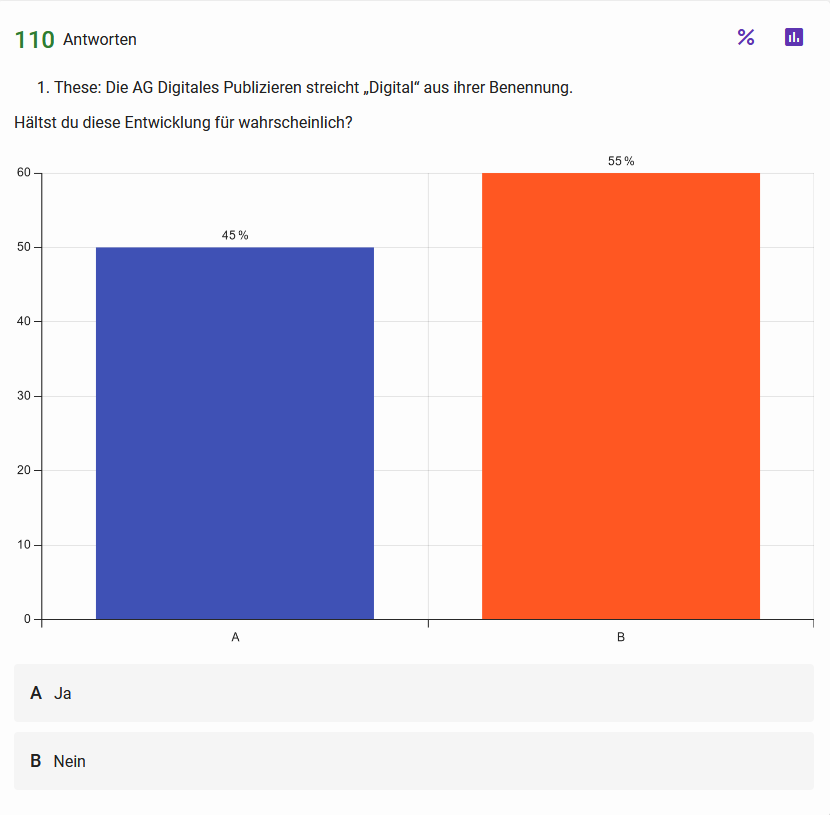
These 1: Die AG Digitales Publizieren streicht ›Digital‹ aus ihrer Benennung Abb. 1: Haltungen der Teilnehmenden zur ersten These Abb. 2: Einschätzung zur Wahrscheinlichkeit der in These 1 skizzierten Entwicklung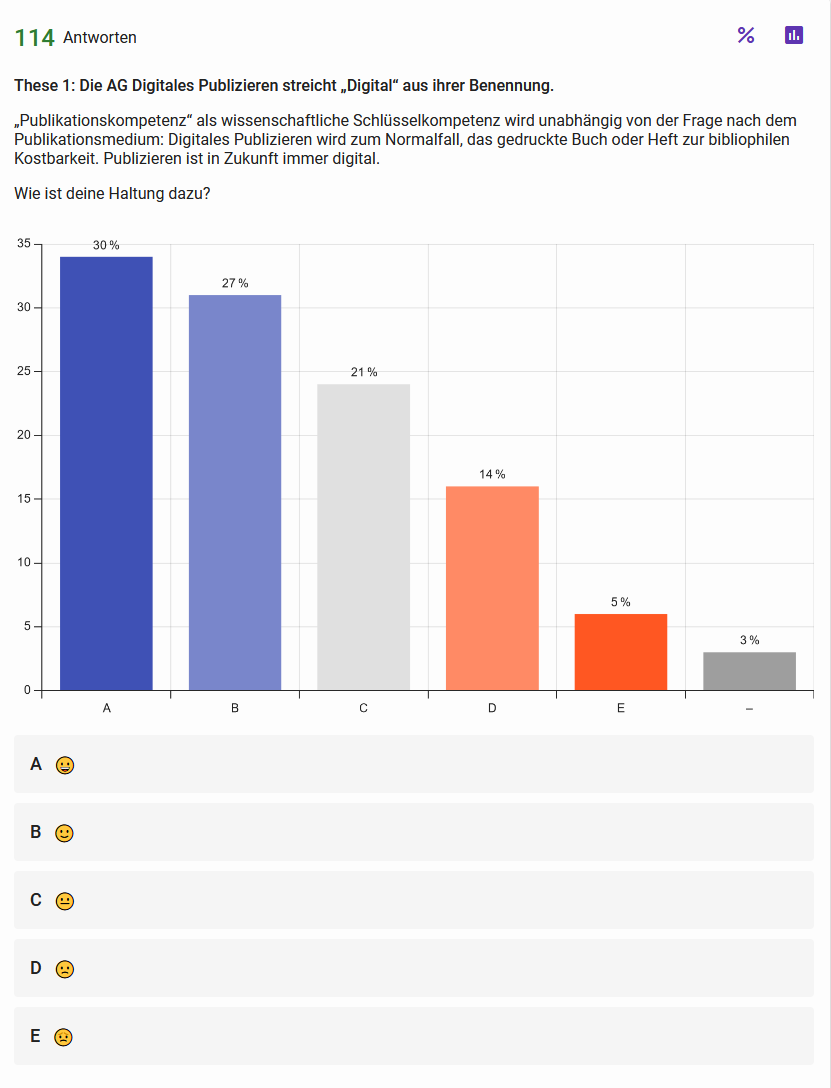{kind=link}
{kind=link}
Auch wenn aktuell noch stark hybrid publiziert wird, war es für uns keine gewagte These, angesichts von Open Access und Open Science von einer zukünftigen Digital-Only-Publikationswelt auszugehen. Für eine Durchsetzung des digitalen Formats sprechen sowohl ökonomische und ökologische Gründe als auch der einfachere Zugriff, höhere Zitationsraten, gesteigerte Interaktivität sowie die Möglichkeit der Ergänzung durch andere Formate wie Forschungsdaten oder Software. Die Antworten zeigen jedoch ein geteiltes Bild: Zwar teilen über die Hälfte der Befragten die Aussage, dass das Publizieren in Zukunft immer digital sein wird. Allerdings hält auch eine knappe Mehrheit das Streichen von digital aus dem AG-Namen für unwahrscheinlich.
Während wir die generelle Zustimmung zur These durchaus erwartet haben, da die Zunahme von digitalen Publikationsangeboten bereits in der Breite der Community wahrgenommen wird, überrascht uns doch die Skepsis gegenüber dem Ändern des AG-Namens. Dies kann aber auch damit zusammenhängen, dass der Begriff ›Publizieren‹ ohne das Adjektiv ›digital‹ traditioneller klingt und auch den Bezug zu den Digital Humanities verliert. Es könnte daher auch als Rückschritt wahrgenommen werden. Man könnte auch sagen: Solange die Digital Humanities ihren Namen nicht ändern, wird es bei der AG Digitales Publizieren bleiben.
Für uns stellt sich auch die Frage, ob wir in Zukunft nicht eher eine neue Abgrenzung zwischen Digital-Publikationen in ›klassischer‹ Text/Bild-Form gegenüber enhanced publications erleben werden, sodass die Trennlinie nicht mehr zwischen gedruckten und digitalen Publikationen, sondern zwischen statischen, textbasierten Veröffentlichungen und multimodalen, interaktiven und vernetzten Publikationsformen verläuft.
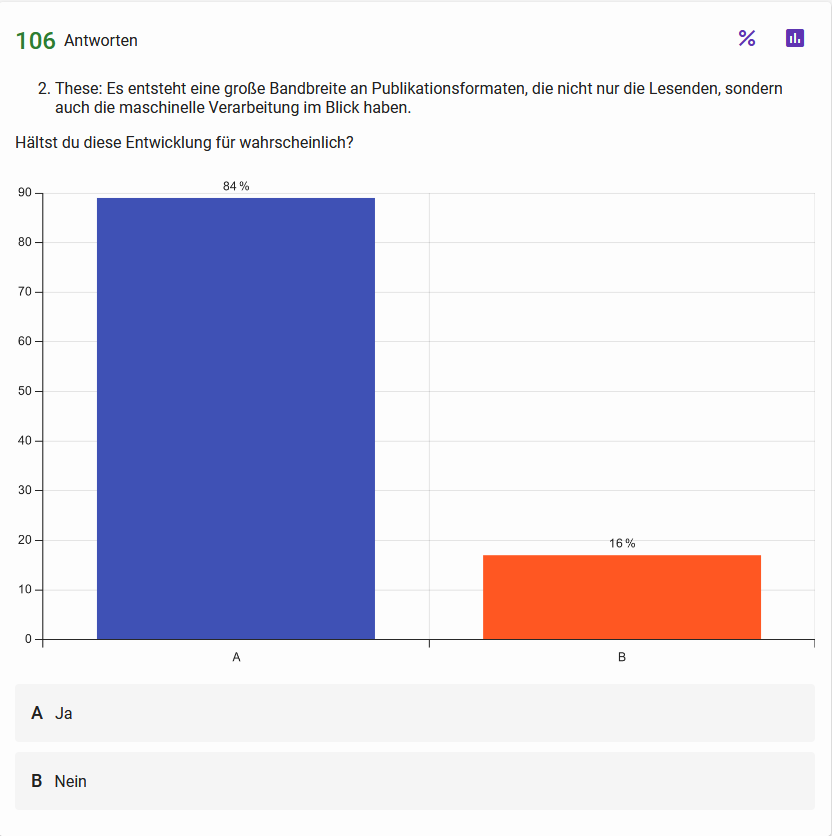
These 2: Es entsteht eine große Bandbreite an Publikationsformaten, die nicht nur die Lesenden, sondern auch die maschinelle Verarbeitung im Blick haben Abb. 3: Haltungen der Teilnehmenden zur zweiten These Abb. 4: Einschätzung zur Wahrscheinlichkeit der in These 2 skizzierten Entwicklung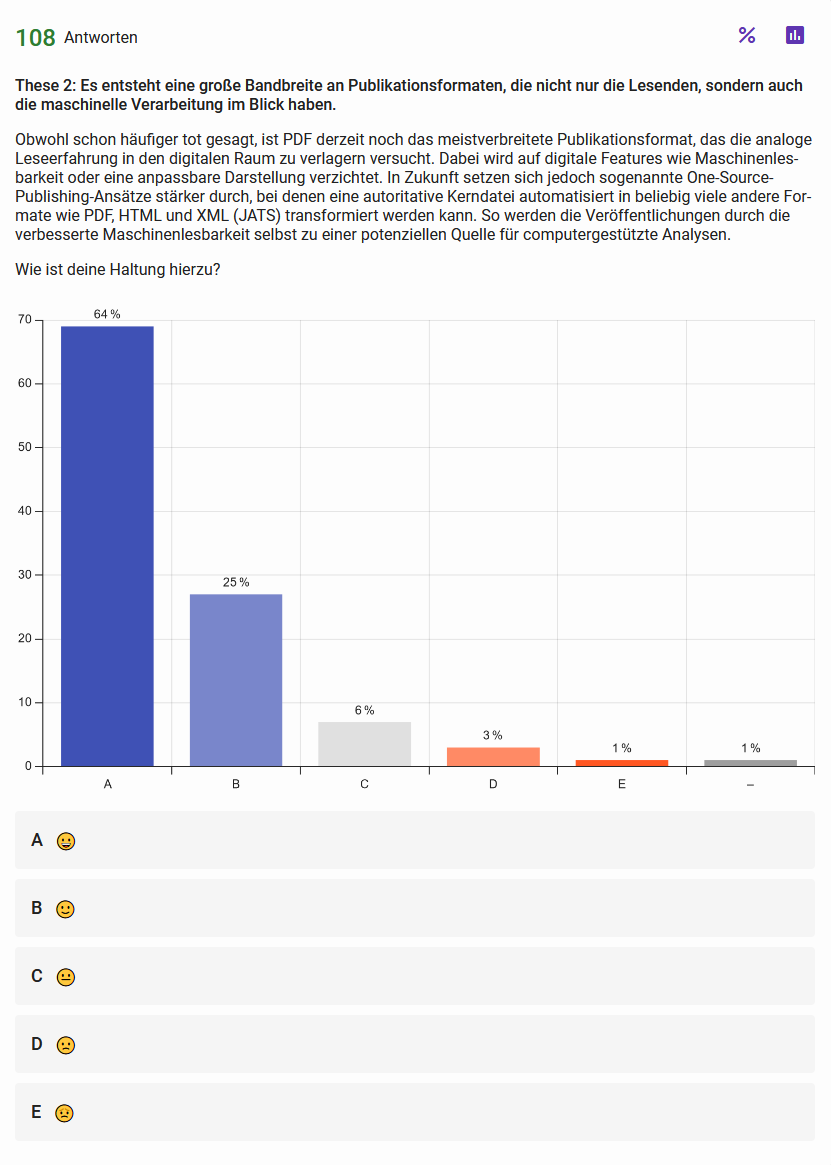{kind=link}
{kind=link}
Die Umfrageergebnisse zeigen eindeutig, dass eine größere Verbreitung von Single-Source-Publishing Ansätzen und die damit einhergehende Verbreitung von maschinenlesbaren Publikationsformaten als positiv und wahrscheinlich angesehen werden.
Obwohl keine Daten zu konkreten Hintergründen der befragten Personen vorliegen, kann davon ausgegangen werden, dass die meisten Teilnehmer*innen wahrscheinlich technikaffin sind und entsprechend ein gesteigertes Interesse an Publikationen in maschinenlesbaren Formaten für die eigene computergestützte Forschung mitbringen. Handelt es sich somit bei den Umfrageergebnissen um ein überproportional vertretenes Wunschdenken einiger weniger Enthusiast*innen, das bereits im AG Working Paper von 2021 (AG Digitales Publizieren 2021) formuliert wurde, aber bisher zumindest in der Breite zu eher übersichtlichen Veränderungen in der Publikationspraxis geführt hat? Zumindest die auch in absoluten Zahlen relativ hohe Teilnahmequote der Umfrage zeigt, dass die Forderung nach zunehmender Verbreitung nativ-digitaler Publikationsformate mindestens kein Randphänomen mehr ist. Und selbst wenn es sich derzeit noch um ein primär innerhalb der DH-Community verbreitetes Anliegen handeln sollte, wird dies mittel- bis langfristig auch zu Änderungen in der Publikationspraxis führen. Dies liegt daran, dass viele der Befragten selbst publizieren und/oder verlegen und es dank der genannten Single-Source-Publishing-Ansätze nicht mehr um ein Entweder-Oder, sondern vielmehr um ein Sowohl-als-Auch geht.
Nicht die Umstellung von PDF auf ein XML-Format wird also zu einer größeren Verbreitung von maschinenlesbaren Publikationsformaten führen, sondern vor allem die zunehmende Verbreitung sogenannter Single-Source-Publishing Ansätze (z.B. mit Hilfe von Pandoc) wird dazu beitragen, dass neben dem gewohnten PDF ohne großen zusätzlichen Aufwand weitere Formate wie HTML, XML/JATS, LaTeX, Markdown und mehr angeboten werden können. Damit können die Veröffentlichungen durch die verbesserte Maschinenlesbarkeit selbst zu einer potenziellen Quelle für computergestützte Analysen werden, ein flexibleres Leseerlebnis bieten und trotzdem auch weiterhin als PDF angeboten werden.
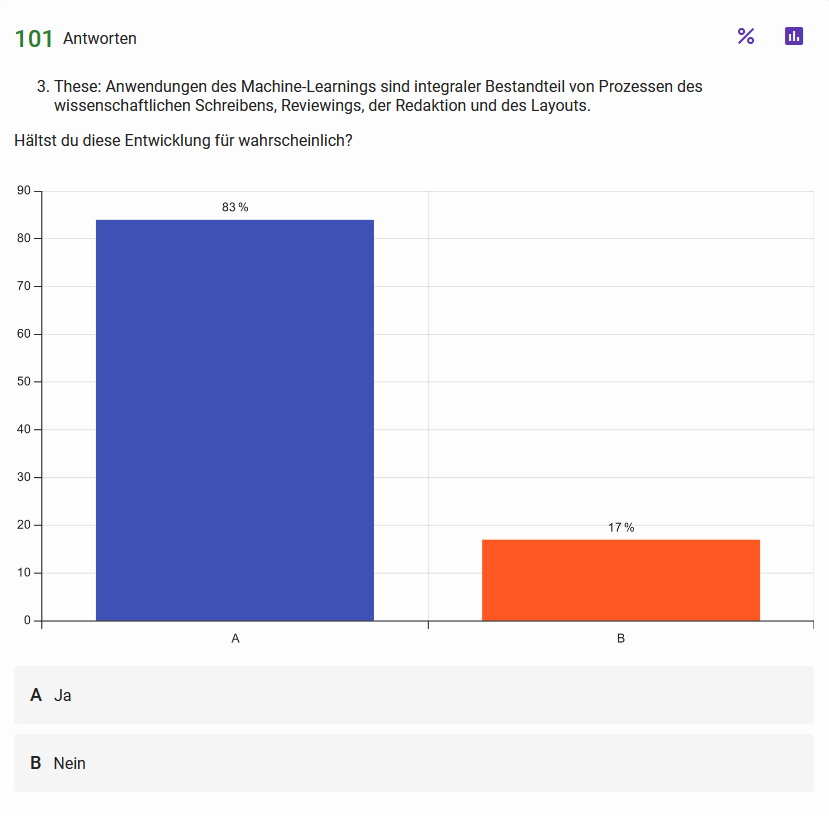
These 3: Anwendungen des Machine-Learnings sind integraler Bestandteil von Prozessen des wissenschaftlichen Schreibens, Reviewings, der Redaktion und des Layouts Abb. 5: Haltungen der Teilnehmen zur dritten These Abb. 6: Einschätzung zur Wahrscheinlichkeit der in These 3 skizzierten Entwicklung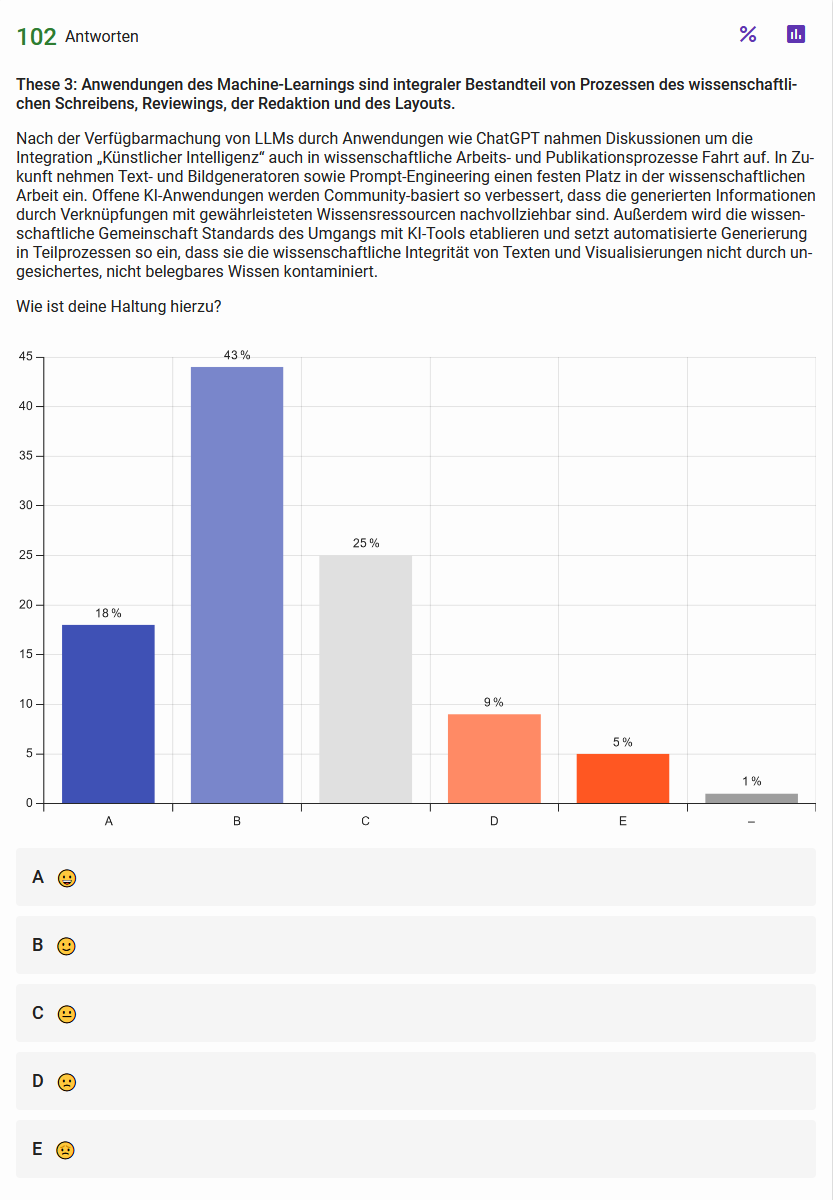{kind=link}
{kind=link}
Auch auf der DHd-Konferenz in Passau waren LLMs das beherrschende Thema in vielen Vorträgen, Panels, Workshops und Diskussionen bis hin zur Gründung der neuen Arbeitsgruppe Angewandte Generative KI in den Digitalen Geisteswissenschaften (AGKI-DH). Die Umfrageergebnisse zeigen eine deutliche Mehrheit im Feld der zustimmenden Haltung gegenüber dieser Entwicklung. Noch positiver ist die Frage nach der Wahrscheinlichkeit der skizzierten Entwicklung beantwortet worden.
Die ausgeprägt zustimmende Haltung gegenüber der Integration von LLMs in wissenschaftliche Publikationsprozesse lässt sich vermutlich ebenfalls mit den Hintergründen und Grundhaltungen der – in der Regel als eher technikaffin bekannten – DHd-Mitglieder bzw. Empfänger*innen der adressierten Mailinglisten erklären und fiele in eher traditionellen Kreisen geisteswissenschaftlicher Disziplinen vermutlich anders aus. Die sogenannte Künstliche Intelligenz wird in den DH stärker als Implementierung bestimmter Machine-Learning-Algorithmen und damit als für die eigenen Zwecke nutzbares und tendenziell hilfreiches, jedenfalls weniger bedrohliches Werkzeug verstanden. Zudem ist in den DH das Schreiben eines Papers häufig ›nur‹ die Dokumentation des eigentlichen Forschungsprozesses und weniger selbst als z.B. argumentierender, theoretisierender etc. Beitrag der Hauptaspekt der Forschung, wie es in nicht-digitalen geisteswissenschaftlichen Disziplinen häufig der Fall ist. Zudem leidet die Forschung weniger unter Restriktionen im Umgang mit LLMs als die Hochschullehre, die an vielen Standorten durch Eingriffe und Vorgaben der Hochschulleitungen in der Anwendung von LLMs und Machine Learning streng begrenzt wird. Die affirmative Haltung zum Einsatz von LLMs bei der Publikation von Forschungsbeiträgen ließe sich also auch als Gegenbewegung zu sonstigen Begrenzungen interpretieren.
Immerhin scheint jedoch auch im DH-Bereich noch ein Viertel der Teilnehmenden nicht zu einer eindeutigen positiven oder negativen Einschätzung gekommen zu sein. Einen Grund dafür sehen wir darin, dass wir in unserer These mehrere Aspekte berühren, zu denen Teilnehmende vielleicht divergierende Meinungen haben, aber nur eine Gesamtantwort geben konnten. So könnte man dem Aspekt einer offenen, Community-basierten Variante von LLMs positiv gegenüber stehen, um nicht zuletzt eine »explainable AI« zu erreichen, die Integration in sämtliche Arbeitsprozesse des Publizierens aber kritisch sehen. »Explainable AI« kann dabei als Dachkonzept für verschiedene Aspekte verstanden werden, wie etwa »(i) data explainability, (ii) model explainability, (iii) posthoc explainability, and (iv) assessment of explanations« (Ali et al. 2023, Abstract).
Auch zur inhärenten Frage, ob und wie wir zukünftig mit kommerziellen LLM-Anbietern kooperieren wollen, gibt es divergierende Meinungen, die zu einer neutralen Gesamteinschätzung geführt haben können. Das brandaktuelle Thema um ›KI‹ muss sich aus seinem momentanen Hype-Status hinausentwickeln, damit wir auf Grundlage konkreter Erfahrungen zu belegbaren Einschätzungen kommen können.
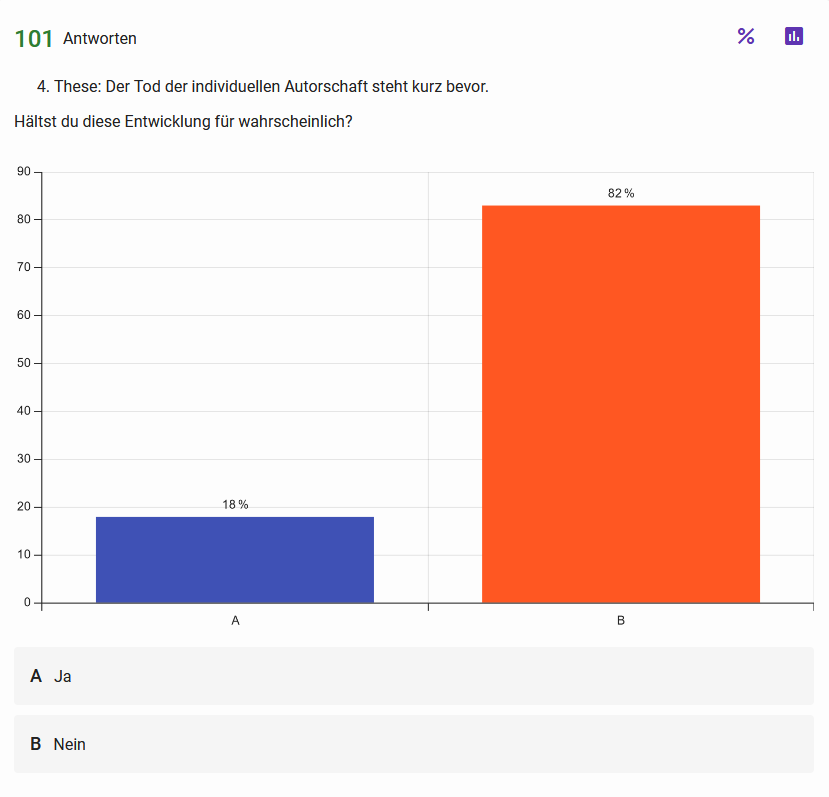
These 4: Der Tod der individuellen Autorschaft steht kurz bevor Abb. 7: Haltungen der Teilnehmenden zur vierten These Abb. 8: Einschätzung zur Wahrscheinlichkeit der in These 4 skizzierten Entwicklung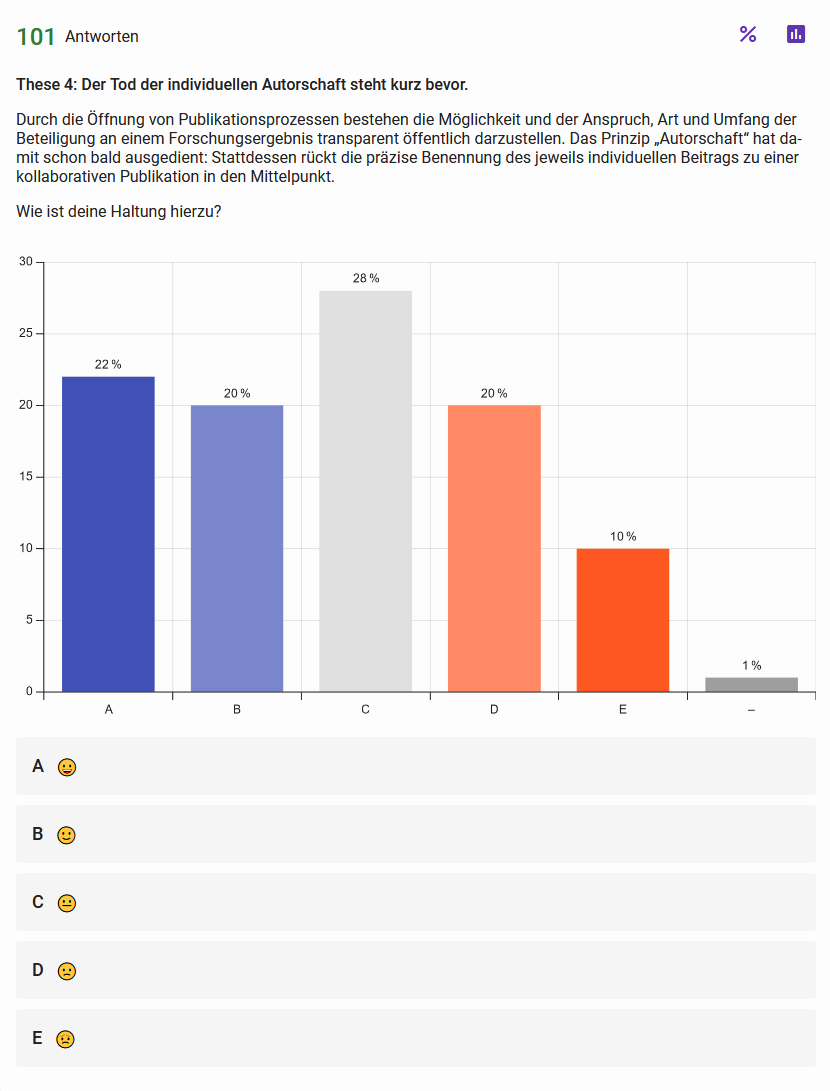{kind=link}
{kind=link}
Die Ergebnisse der Einstellungsabfrage zur These der individuellen Autorschaft fallen im Vergleich zu den anderen deutlich ambivalenter und weniger positiv aus, die Diskrepanz zu den sehr niedrigen Ablehnungswerten bei anderen Fragen ist deutlich.
Ähnliches gilt für die Frage nach der Wahrscheinlichkeit, dass diese Entwicklung eintritt: Hier zeigt sich die deutlichste Negativtendenz der gesamten Umfrage. Die DH-Community hält die Entwicklung, dass das Prinzip der individuellen Autorschaft bald ausgedient hat, also sowohl für ziemlich unwahrscheinlich als auch für eher weniger wünschenswert als andere Entwicklungen.
Der die These erläuternde Text zieht keine Querverbindungen zu den Thesen 3 und 5, wobei diese Thesen das Konzept der individuellen Autorschaft – These 3 im Spannungsfeld von intellektueller Leistung und Automatisierung, These 5 hinsichtlich des Produkts von Autorschaft – berühren und infrage stellen. Durch diese verkürzte Darstellung sowie die Tatsache, dass Autorschaft von Publikationen karriereentscheidend ist, könnte sich die ablehnende Haltung vieler Befragter erklären lassen. Zudem ist das Thema nicht neu oder gar unerforscht: Bereits Nyhan und Duke-Williams entlarven einerseits das »multi-authored Digital Humanities paper« und andererseits den/die »Humanities lone scholar« jeweils als Stereotype (Nyhan / Duke-Williams 2014, S. 387). Ihre Analyse zeigt, dass Einzelautorschaft auch in den Digital Humanities weiterhin die kollaborative Autorschaft (von zwei oder mehr Autor*innen) überwiegt (auch wenn leichte Trends zu mehr Kollaboration erkennbar sind) (vgl. Nyhan / Duke-Williams 2014, S. 395). Auch die Auswertungen der Beiträge der Zeitschrift für digitale Geisteswissenschaften (ZfdG) sowie die (teilweise stichprobenartig ermittelte) von deren Redaktion erstellte Übersicht zu kollaborativer Autorschaft in sechs weiteren internationalen DH-Journals (Zeitraum: 2015 bis 2023) zeigen zumindest kein einheitliches Bild: In den meisten Fällen halten sich Einzel- und kollaborative Autorschaft weitgehend die Waage (vgl. Baumgarten et al. 2024a; Baumgarten et al. 2024b). Zudem wurden in beiden hier referenzierten Untersuchungen ausschließlich Beiträge in wissenschaftlichen Journals betrachtet, der in den Geisteswissenschaften weiterhin relevante Sektor der Monografien, zu dem auch der Bereich der zwingend in Einzelautorschaft erscheinenden Qualifizierungsarbeiten zählt, wurde völlig außer Acht gelassen. Von einem ›Abschaffen‹ der individuellen Autorschaft in den digitalen Geisteswissenschaften kann also tatsächlich keine Rede sein.
Die Disziplin ist dennoch geprägt von inter- und transdisziplinären Perspektiven und der Übertragung von methodischen Ansätzen aus anderen Wissenschaftsbereichen zur Erforschung geisteswissenschaftlicher Fragestellungen; dieses Überschreiten der Grenzen traditioneller Wissenschaftsbereiche führte anfänglich wahrscheinlich wirklich zu einem erhöhten Kollaborationsbedarf, da man auf die personelle Expertise aus unterschiedlichen Fachbereichen angewiesen war. Je länger die Disziplin besteht und je mehr eigene Lehrstühle und Studiengänge eingerichtet werden, desto eher ist zu erwarten, dass die erforderlichen Kompetenzen auch von Einzelpersonen erworben werden können, wodurch die Notwendigkeit von Kollaborationen möglicherweise abnimmt. Dem entgegen stehen allerdings Entwicklungen wie die vermehrte Anzahl von Forschungsverbünden und fächerübergreifenden Sonderforschungsbereichen, der »›small discipline‹ effect« (Nyhan / Duke-Williams 2014, S. 396) und verstärkte Bestrebungen zur internationalen Zusammenarbeit.
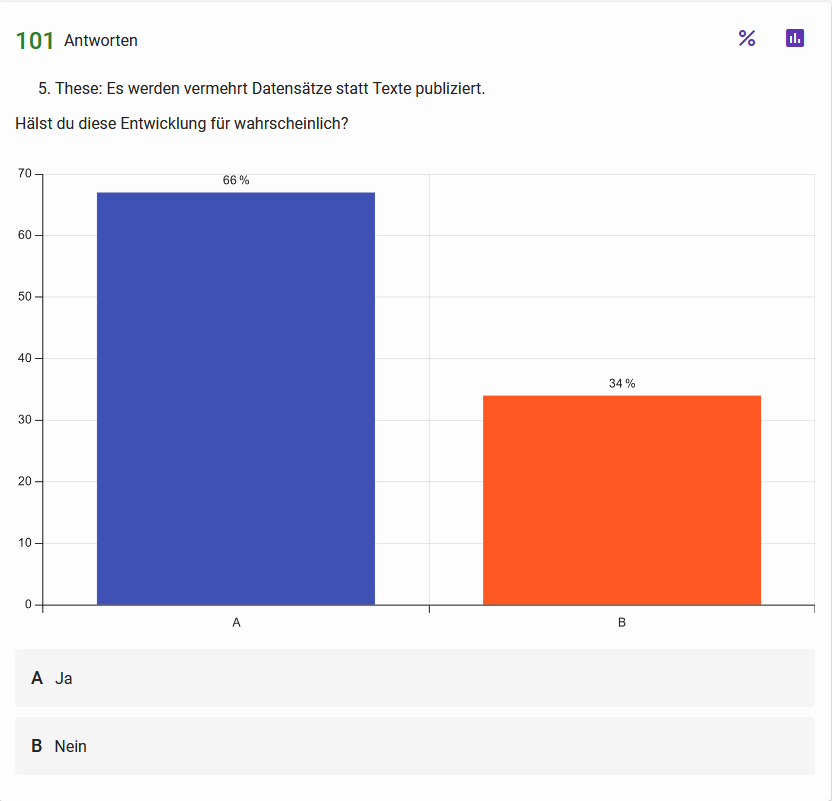
These 5: Es werden vermehrt Datensätze statt Texte publiziert Abb. 9: Haltungen der Teilnehmenden zur fünften These Abb. 10: Einschätzung zur Wahrscheinlichkeit der These 5 skizzierten Entwicklung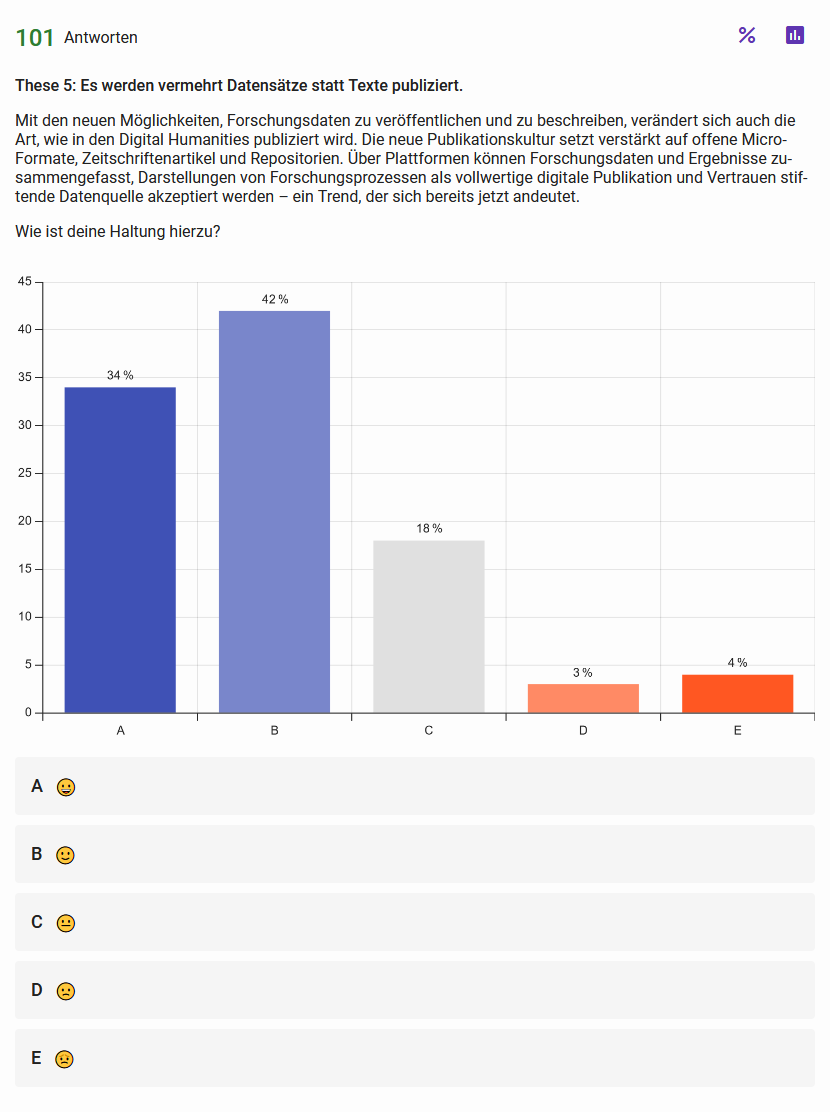{kind=link}
{kind=link}
Wenn wir die Genese des Book of Abstracts der DHd-Konferenzen von Konferenzabstracts in einem ›gebundenen Buch‹ über Micro-Veröffentlichungen hin zu wissenschaftlichen Publikationen betrachten, wird die Veränderung digitalen Publizierens deutlich (vgl. Helling et al. 2022). Daher verwundert es nicht, dass die meisten der Befragten die künftig stärkere Zunahme der Publikation von Datensätzen als wahrscheinlicher einschätzen als die von Texten.
Hinzu kommt, dass Forschungsdaten im Zuge wissenschaftlicher Erkenntnisprozesse an vielen Stellen entstehen. Während bei der Erstveröffentlichung des Grundlagenwerks Digital Humanities. Eine Einführung Forschungsdaten als »extensivere Publikationstätigkeit als dies unter naturgemäß begrenzten Druckbedingungen gegeben« gesehen wurden, die »vorstellbar und zur Zeit schon sporadisch praktiziert« (Kohle 2017, S. 201) werde, hat sich die Kultur des Publizierens in den Digital Humanities tatsächlich in die prognostizierte Richtung weiterentwickelt. Die Publikation von Forschungsdaten ist ein wichtiger Beitrag zur Überprüfbarkeit der Datengrundlage und damit der Einhaltung guter wissenschaftlicher Praxis (vgl. Deutsche Forschungsgemeinschaft 2022).
Außerdem wird vor dem Hintergrund aktueller gesellschaftlicher Entwicklungen (vgl. Wissenschaft im Dialog 2023) die Offenlegung der Quelldaten einer Arbeit als vertrauensstiftende Maßnahme in die Wissenschaft betrachtet (vgl. Mößner 2022). Hinzu kommt, dass unstrukturierte Datensätze durch den Einsatz von ›KI‹ oder Big-Data-Methoden (vgl. Gelfert 2022) leichter selbst zum Forschungsgegenstand werden können. Die Entwicklung neuer Analysemethoden wiederum kann Rückwirkungen darauf haben, in welcher Art und in welchem Umfang Primär- und Forschungsdaten publiziert werden. Damit einhergehend steigt die Wahrscheinlichkeit, dass in Zukunft auch vermehrt Datensätze veröffentlicht werden. Ob klassische Formen des Publizierens wissenschaftlicher Texte dabei allerdings abgelöst oder nur ergänzt werden, wird die Zukunft zeigen.
Zusammenfassung der ErgebnissePublizieren verändert sich (vgl. Cremer 2018). Diese Veränderungen möchte die AG Digitales Publizieren auch in Zukunft kritisch begleiten und für die DH-Community fruchtbar und nutzbar machen. Die von uns skizzierten Entwicklungen wurden von der Community insgesamt positiv bewertet und auch als wahrscheinlich angesehen. Sie beziehen sich allerdings auch auf Prozesse, die bereits begonnen haben bzw. sich schon längere Zeit abzeichnen – größere Überraschungen waren an dieser Stelle also nicht zu erwarten.
Allerdings gab es zwischen den einzelnen Thesen doch wahrnehmbare Unterschiede in der Einschätzung: Während beispielsweise Single-Source Publishing Ansätze und damit einhergehende zusätzliche Publikationsformate wie JATS/XML oder HTML als durchweg positiv und wahrscheinlich angesehen wurden, waren die Meinungen zum Einfluss von ›KI‹ auf den Publikationsprozess und zur Rolle individueller Autorschaft deutlich durchwachsener. Die Gründe hierfür sind wie dargestellt komplex und nicht bis ins Detail aufzulösen. Für das derzeit wohl einflussreichste und sich im stetigen Wandel befindliche Thema ›KI‹ erscheinen die Antwortmöglichkeiten zu undifferenziert und die Bedeutung, die individuelle Autorschaft nicht nur für die Wissenschaft, sondern auch für die Wissenschaftler*innen im Rahmen der individuellen Karriere hat, blieb in der These unterbelichtet. Insbesondere die wissenschaftspolitischen Implikationen der Wandlungen des Publikationssektors möchte die AG deshalb in Zukunft verstärkt und kritisch in den Blick nehmen. Hierzu findet am 8. und 9. Oktober 2024 in Darmstadt eine Tagung zum Thema Reputation ohne Paywall? Wissenschaftliches Publizieren im digitalen Wandel statt, die die AG anlässlich ihres zehnjährigen Bestehens veranstaltet. Wir freuen uns über rege Teilnahme aus der Community.
Die genannten Thesen zur ›KI‹, zu multimodalen, datengetriebenen Publikationen und zur Rolle der Autorschaft sind außerdem durchaus miteinander verbunden, was der zunehmende Einfluss von LLMs auf den Schreib- und auch Analyseprozess auf die akademische Lehre und Forschung zeigt, der nicht zuletzt die individuelle Autorschaft infrage stellt. In Zukunft möchten wir deshalb die Zusammenarbeit mit anderen DHd-AGs, insbesondere der AG Angewandte Generative KI in den Digitalen Geisteswissenschaften sowie der AG Datenzentren intensivieren. Interne Gespräche, gemeinsame Veranstaltungen, Publikationen oder andere Formate sind dabei denkbar – wir melden uns bei euch! Dies wäre nicht nur für die Mitglieder der AGs von Interesse, sondern scheint zumindest der Umfrage nach zu urteilen auch für weitere Kreise innerhalb der DH-Community relevant zu sein.
Für die AG Digitales Publizieren selbst bedeuten die Ergebnisse kurz- bis mittelfristig, dass auch wir insbesondere den divers diskutierten Themen ›KI‹ und Autorschaft, zu denen es offensichtlich verstärkten Diskussions- und Klärungsbedarf gibt, mehr Raum geben wollen und unsere Angebote und Schwerpunkte entsprechend anpassen. Beginnen wollen wir damit, die oben aufgeworfene Frage nach der Rolle von ›KI‹ für die Autorschaft genauer zu untersuchen.
Bibliografie- AG Digitales Publizieren (Hg): Digitales Publizieren in den Geisteswissenschaften. Begriffe, Standards, Empfehlungen (= Zeitschrift für digitale Geisteswissenschaften / Working Papers, 1). Erstveröffentlichung vom 18.03.2021. Version 2.0 vom 09.03.2023. Wolfenbüttel 2021. DOI: 10.17175/wp_2021_001_v2DHd AG Working Paper 2021
- Sajid Ali / Tamer Abuhmed / Shaker El-Sappagh / Khan Muhammad / Jose M. Alonso-Moral / Roberto Confalonieri / Riccardo Guidotti / Javier Del Ser / Natalia Díaz-Rodríguez / Francisco Herrera: Explainable Artificial Intelligence (XAI). What We Know and What Is Left to Attain Trustworthy Artificial Intelligence. In: Information Fusion 99 (2023), Art. 101805. DOI: 10.1016/j.inffus.2023.101805
- Marcus Baumgarten / Henrike Fricke-Steyer / Martin de la Iglesia / Caroline Jansky / Jonathan Schimpf / Martin Wiegand (2024a): Transparenz im Fokus. Die Publikationspraxis der Zeitschrift für digitale Geisteswissenschaften. Poster im Rahmen der DHd2024 (Passau, 26.02.2024 — 01.03.2024). 21.02.2024. DOI: 10.5281/zenodo.10706093
- Marcus Baumgarten / Martin de la Iglesia / Caroline Jansky / Martin Wiegand / Jonathan Schimpf (2024b): Publikationspraxis der Zeitschrift für digitale Geisteswissenschaften 2015 bis 2023. Datenset. 26.02.2024. DOI: 10.17175/2015-2023_publikationspraxis-zfdg
- Deutsche Forschungsgemeinschaft: Guidelines for Safeguarding Good Research Practice. Code of Conduct. 2022. DOI: 10.5281/zenodo.6472827
- Fabian Cremer: Nun sag, wie hältst Du es mit dem Digitalen Publizieren, Digital Humanities? Eine retrospektive Gretchenfrage an die #DHd2018. In: Digitale Redaktion. Editorial zum digitalen Publizieren. 21.03.2018. Online: https://editorial.hypotheses.org/113
- Patrick Dinger / Jan Horstmann / Caroline Jansky / Thomas Jurczyk / Timo Steyer (2024a): ›Roads? Where we’re going, we don’t need roads.‹ Die Zukunft des Publizierens. Poster im Rahmen der DHd2024 (Passau, 26.02.2024 — 01.03.2024). 21.02.2024. DOI: 10.5281/zenodo.10706061
- Patrick Dinger / Jan Horstmann / Caroline Jansky / Thomas Jurczyk / Timo Steyer (2024b): ›Roads? Where we’re going, we don’t need roads.‹ Die Zukunft des Publizierens. Abstract im Rahmen der DHd2024 (Passau, 26.02.2024 — 01.03.2024). 21.02.2024. DOI: 10.5281/zenodo.10698293
- Axel Gelfert: Gesellschaftliche Erwartungen an ›Big Data‹ in der Wissenschaft. Zur Mär vom ›Ende der Theorie‹. In: Nicola Mößner / Klaus Erlach (Hg.): Kalibrierung der Wissenschaft: Auswirkungen der Digitalisierung auf die wissenschaftliche Erkenntnis. Bielefeld 2022, S. 23–42. DOI: 10.1515/9783839462102-002
- Patrick Helling / Anke Debbeler / Rebekka Borges: Konferenzbeiträge strategisch publizieren. Automatisierte Workflows zur individuellen Veröffentlichung von Konferenzbeiträgen am Beispiel des Verbands Digital Humanities im deutschsprachigen Raum e.V. In: O-Bib. Das Offene Bibliotheksjournal 2022, H. 3, S. 1–17. DOI: 10.5282/o-bib/5835
- Hubertus Kohle: Digitales Publizieren. In: Fotis Jannidis / Hubertus Kohle / Malte Rehbein (Hg.): Digital Humanities. Eine Einführung. Stuttgart 2017, S. 199–205.
- Nicola Mößner: Wissenschaft in ›Unordnung‹? Gefiltertes Wissen und die Glaubwürdigkeit der Wissenschaft. In: Nicola Mößner / Klaus Erlach (Hg.): Kalibrierung der Wissenschaft: Auswirkungen der Digitalisierung auf die wissenschaftliche Erkenntnis. Bielefeld 2022, S. 103–136. DOI: 10.1515/9783839462102-005
- Julianne Nyhan / Oliver Duke-Williams: Joint and Multi-authored Publication Patterns in the Digital Humanities. In: Literary and Linguistic Computing 29 (2014), H. 3. 01.09.2014. DOI: 10.1093/llc/fqu018
- Wissenschaft im Dialog: Wie sehr vertrauen Sie Wissenschaft und Forschung? Chart. In: Statista. 05.12.2023. Online: https://de.statista.com/statistik/daten/studie/1193534/umfrage/vertrauen-in-wissenschaft-und-forschung/
Einladung zum (Online-)Vortrag „Frauen im frühromantischen Briefnetzwerk” von Elena Suárez Cronauer am 3. Juli
Am 3. Juli 2024 stellt Elena Suárez Cronauer das DFG-Projekt „Korrespondenzen der Frühromantik” vor und berichtet, wie mit geschlechtsspezifischen Herausforderungen bei der quantitativen Untersuchung von Frauen im Netzwerk umgegangen werden kann.
Die Jenaer (und Berliner) Frühromantik gilt als die herausragende intellektuelle Revolution junger deutscher Autor*innen und Gelehrter an der Epochenschwelle um 1800. Innerhalb ihres Briefnetzwerks, das im DFG-Projekt „Korrespondenzen der Frühromantik” modelliert wird, finden sich zahlreiche Briefe dieser romantischen Autorinnen und Akteurinnen, z.B. von Dorothea Schlegel, Caroline Schlegel(-Schelling), Sophie Tieck-Bernhardi oder Rahel Levin Varnhagen. Allerdings stellen sich bei der quantitativen Untersuchung von Frauen im Netzwerk einige geschlechtsspezifische Herausforderungen wie lückenhafte Überlieferung der Briefe oder fehlende Informationen über Frauen in Normdatensystemen, um nur einige zu nennen.
Wie können also solche marginalisierten Gruppen mit Methoden der historischen Netzwerkanalyse untersucht werden, ohne dass biases in den (bereits edierten) Quellen, die sich in den Daten widerspiegeln, unreflektiert wiederholt und somit weitergetragen werden? Welche Potentiale hat wiederum die quantitative Betrachtung solcher Gruppen im Gegensatz zu einem rein qualitativen Vorgehen? Im Vortrag sollen diese Ansätze zur Untersuchung sowie Ideen zum Umgang mit den genannten Herausforderungen vorgestellt und diskutiert werden.
Der Vortrag findet am 3. Juli 2024 von 10 bis 12 Uhr (c.t.) im Raum A11 an der Universität Trier und via Zoom statt.
Den Zoomlink und alle Informationen zum Vortrag gibt es unter: https://tcdh.uni-trier.de/de/event/frauen-im-fruehromantischen-briefnetzwerk
Wir freuen uns auf Sie!
{kind=link}
Fehlerdokumentation des Book of Abstracts DHd 2024
Autor:innen
Nicole Majka | Bangor University, Wales | ORCID: 0000-0003-2657-0645
Patrick Helling | Verband Digital Humanities im deutschsprachigen Raum e.V. | ORCID: 0000-0003-4043-165X
(siehe auch –> https://zenodo.org/doi/10.5281/zenodo.11258737)
Die DHd Jahreskonferenz 2024 trug den Titel “#Quo vadis DH?”, fand vom 26. Februar 2024 bis zum 1. März 2024 statt und wurde an der Universität Passau ausgerichtet.[1] Die Software ConfTool,[2] welche zur Konferenzverwaltung genutzt wurde, wurde am 12. Juni 2023 freigeschaltet. Über dieses Tool konnten Autor:innen sich zur Konferenz anmelden und Beiträge einreichen. Autor:innen gaben hierzu Metadaten wie bspw. den Beitragstitel, Autor:innennamen mit Affiliation und ORCID-ID und Keywords zu einer Einreichung über das ConfTool ein. Die Metadaten wurden schließlich aus dem ConfTool über eine Schnittstelle an den DHConvalidator[3] übertragen, in dem ein Template für jede Einreichung inklusive aller zugehörigen Metadaten erzeugt und von den Autor:innen zur Erstellung ihrer Einreichung genutzt wurde. Nachdem die Autor:innen ihren Beitrag im Template geschrieben hatten, wurde dieses über den DHConvalidator prozessiert, sodass eine .dhc-Datei mit einer HTML-, einer Template- und einer TEI-XML-Version der Einreichung sowie eingebetteter Abbildungen erzeugt wurde. Diese wurde schließlich durch die Autor:innen als Beitrag im ConfTool hochgeladen und eingereicht. Mit Hilfe der eingetragenen Metadaten wurden schließlich aus den TEI-XML-Versionen der eingereichten und akzeptierten Beiträge das Book of Abstracts sowie Einzelpublikationen der Beiträge über automatisierte Workflows[4] generiert (Helling et al. 2022a).
Für diese automatisierte Erstellung des Book of Abstracts sowie der Einzelpublikationen wurden die eingereichten TEI-XML-Versionen der Beiträge verwendet. In der Regel sind die TEI-XML-Versionen der Beiträge unsauber und können Fehler aufweisen, die händisch korrigiert werden müssen. Diese Fehler sind prinzipiell auf falsche Formatierungen sowie die Übernahme von Formatierungsinformationen beim Kopieren eines Beitrags aus einem anderen Textverarbeitungsprogramm in das Template durch die Autor:innen zurückzuführen (Helling et al. 2022b). Mit diesem Beitrag sollen jene Fehler exemplarisch für die DHd Jahreskonferenz 2024 dokumentiert werden.
EinführungZur Jahreskonferenz 2024 wurden insgesamt 144 Beiträge angenommen: 64 Poster, 7 Panels, 19 Workshops, 43 Vorträge und 11 Beiträge des Doctoral Consortiums. Von vorherigen Jahreskonferenzen waren folgende Fehler aus der Bereinigung der Beiträge bereits bekannt:
- Sonderzeichen im Text (oft auch bei Autor:innenamen in der Bibliographie) werden als # dargestellt
- Autor:innennamen sind in der Bibliographie nicht fett gedruckt
- Abbildungen fehlen im Beitrag oder werden fehlerhaft dargestellt
- Tabellen fehlen im Beitrag oder werden fehlerhaft dargestellt
- Bildunterschriften fehlen oder werden fehlerhaft dargestellt
Zusätzlich zu den schon bekannten Fehlern wurden auch weitere Fehler aufgezeichnet, die seltener vorkommen, aber ebenfalls korrigiert werden mussten. Diese wurden im Folgenden unter der Kategorie “sonstige Fehler” zusammengefasst. Dabei handelte sich unter anderen um folgende Fehler:
- Abstände zwischen Fließtext, Tabellen oder Bildern sind nicht einheitlich
- Überschriften sind nicht als solche hierarchisch formatiert
- fehlende bzw. nicht einheitliche Informationen bei Autor:innen (bspw. Affiliation)
- fehlende Bibliografie
- fehlende Titel
- Zeilenabstand ist aufgrund von Fußnotenreferenzierungen nicht einheitlich
- zu große Abstände im Text, wenn Textteile eingeklammert waren
- Probleme bei URLs (automatische Silbentrennung führt zu ungewollten Bindestrichen in Links und somit zu nicht funktionalen Links)
- fehlende Satzzeichen
Die folgende Tabelle 1 enthält eine Zusammenfassung aller Formatierungsfehler der Beiträge zur DHd 2024 vor der Prozessierung zum Book of Abstracts bzw. zu den Einzelpublikationen. Hierbei ist zu beachten, dass nicht alle, aber die Mehrzahl der Beiträge, fehlerhaft waren. Die unterschiedlichen Fehler der Kategorie “sonstige Fehler” wurden aus Gründen der Übersichtlichkeit nicht einzeln aufgeführt. Auch hier gibt es Beiträge, die nicht fehlerhaft waren und solche, die mehr als einen Fehler hatten. Daher wird jeder Beitrag, der mindestens einen Fehler der Kategorie “sonstige Fehler” aufwies, nur einmal in dieser Spalte gezählt.
Tabelle 1: Übersicht der Fehlertypen aller Beiträge.
Anzahl BeiträgeSonderzeichenAutor:innen nicht fettAbbildung fehltTabelle fehltFehler bei Bildunterschriftensonstige FehlerFehler gesamtPoster641036112944121Panels735000715Workshops193121151234Doctoral Consortium11271011122Vorträge43121002621Gesamt1443061323780213Bei den 144 Beiträgen, die angenommen wurden, traten in 30 Beiträgen Sonderzeichenfehler auf, bei denen Sonderzeichen als # angezeigt wurden, bei 61 Beiträgen waren die Autor:innennamen in der Bibliographie nicht fett gedruckt, bei drei Beiträgen fehlten die Abbildungen, bei zwei die Tabellen, 37 Beiträge hatten fehlerhafte Bildunterschriften und 80 hatten Fehler der Kategorie “sonstige Fehler”. Insgesamt wurden mindestens 213 Fehler behoben. Diese Zahl ist hier nicht akkurat abgebildet und muss höher angenommen werden, da jeder Beitrag nur einmal in jeder Kategorie aufgeführt wurde, auch wenn mehr als ein Fehler der jeweiligen Kategorien in einem Beitrag auftrat.
{kind=link}
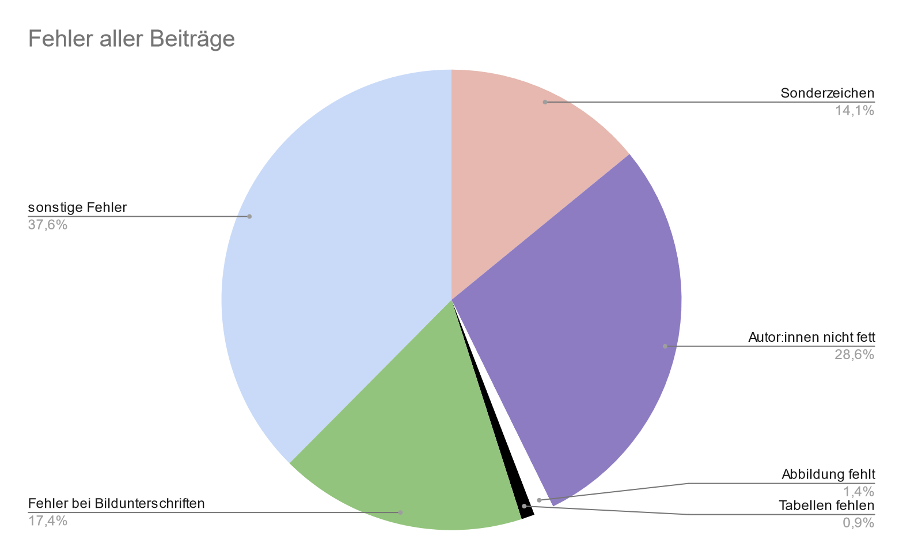
Abbildung 1: Fehleraufteilung aller Beiträge.
In Abbildung 1 wird deutlich, dass die Kategorie “sonstige Fehler” mit 37,6% am häufigsten vorkommt. Dies liegt daran, dass in dieser Kategorie mehr als eine Fehlerart festgehalten wurde. Darauf folgt die Kategorie “Autor:innennamen nicht fett” mit 28,6%. Fehlerhafte Bildunterschriften sind mit 17,4% die dritthäufigste Fehlerkategorie und Sonderzeichenfehler ergeben 14,1% der Fehler. Fehlende Tabellen und Abbildungen liegen gemeinsam bei 2,3%.
Wenn man die Anzahl der Beiträge beachtet, die Abbildungen und Tabellen haben, zeigt sich, dass die Quote der fehlenden Abbildungen und Tabellen vergleichsweise gut ausfällt.
Tabelle 2: Anzahl der Beiträge, die Abbildungen und / oder Tabellen enthalten.
Anzahl der BeiträgeBeiträge mit AbbildungenBeiträge mit TabellenPoster64373Panels700Workshops1982Doctoral Consortium1122Vorträge43309Gesamt1447716Im Vergleich zu Abbildungen kommen Tabellen seltener vor. Von 144 Beiträgen haben nur 16 Beiträge Tabellen, von denen nur zwei nach der automatisierten Generierung fehlten (12,5%). Abbildungen kommen hingegen bei über der Hälfte der Beiträge vor. Von 144 Beiträgen haben 77 Abbildungen, von denen nach der automatisierten Generierung nur drei fehlten (3,8%).
Darüber hinaus sind Fehler in der Formatierung der Bildunterschriften relevant, die aus Gründen der Barrierefreiheit benötigt werden, da sie Lesenden mit eingeschränkter Sehkraft helfen, nachzuvollziehen, was Abbildungen in einem Beitrag zeigen, beispielsweise. wenn ein Screenreader verwendet wird.
Insgesamt hatten 37 Beiträge Fehler bei den Bildunterschriften, wovon die Posterbeiträge den größten Anteil mit 29 fehlerhaften Beiträgen stellen. Das heißt, dass fast die Hälfte (48,1%) der Beiträge mit Bildern falsch formatierte Bildunterschriften hatten.
Die nächsten Kapitel gehen auf die Verteilung der Fehler innerhalb der einzelnen Beitragskategorien ein.
PosterEs wurden insgesamt 64 Posterbeiträge angenommen. Nach der automatisierten Generierung der Beiträge im PDF-Format hatten zehn der Beiträge Sonderzeichenfehler, bei 36 Beiträge waren die Autor:innennamen in der Bibliographie nicht fettgedruckt, in einem Beitrag fehlten Abbildungen und einem weiteren fehlten Tabellen, bei 29 Beiträgen gab es Fehler bezüglich der Formatierung der Bildunterschriften und 44 der Beiträge hatten Fehler der Kategorie “sonstige Fehler” (siehe Abbildung 2). Insgesamt wurden mindestens 121 Fehler behoben.
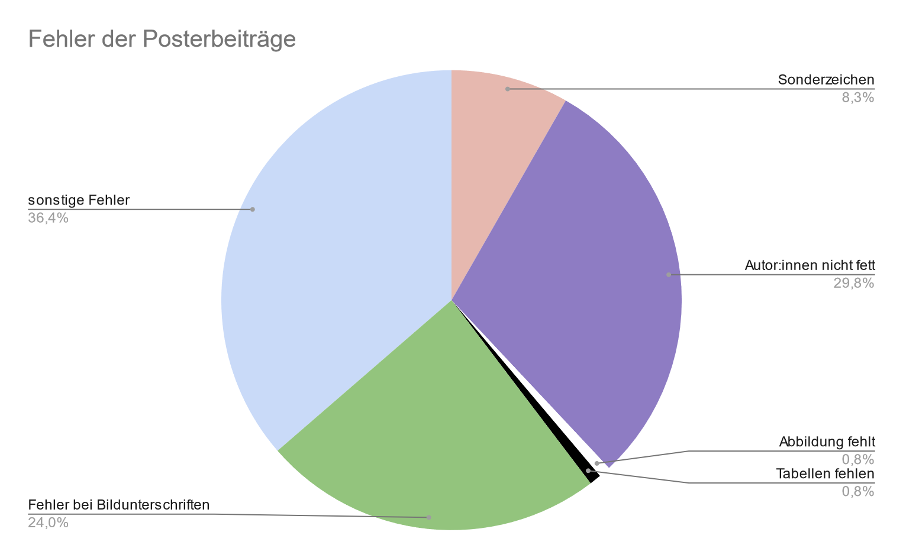{kind=link}
Abbildung 2: Fehleraufteilung der Posterbeiträge.
PanelsBei den 7 Panelbeiträgen, die angenommen wurden, wurden nur drei Fehlerkategorien identifiziert. Drei Beiträge hatten Sonderzeichenfehler, bei fünf Beiträgen waren die Autor:innennamen in der Bibliographie nicht fett gedruckt und alle Beiträge hatten einen Fehler der Kategorie “sonstige Fehler” (siehe Abbildung 3). Insgesamt wurden hier mindestens 15 Fehler behoben.
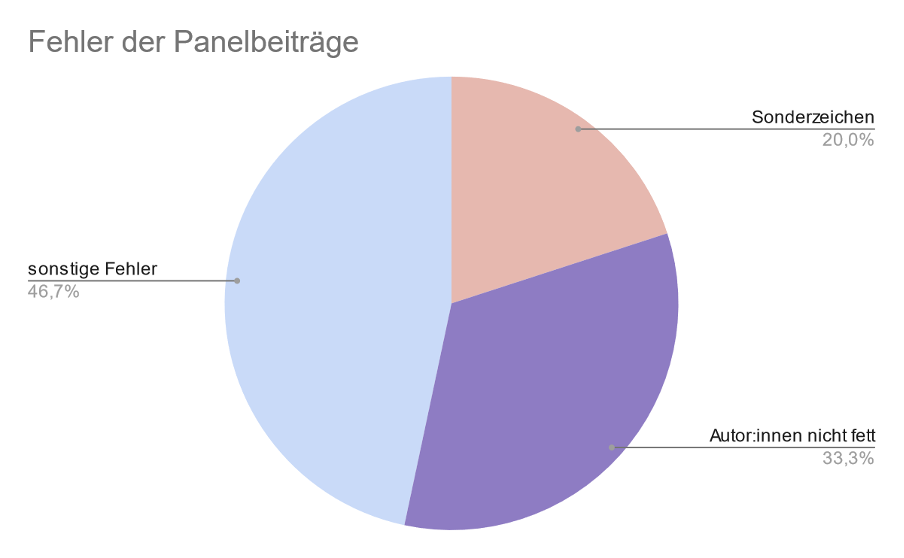{kind=link}
Abbildung 3: Fehleraufteilung der Panelbeiträge.
WorkshopsEs wurden 19 Workshopbeiträge angenommen. Von diesen hatten drei Beiträge Sonderzeichenfehler, bei zwölf Beiträgen waren die Autor:innennamen nicht fett gedruckt, in einem Beitrag fehlten Abbildungen, in einem anderen Tabellen, fünf Beiträge hatten fehlerhafte Bildunterschriften und zwölf Beiträge hatten Fehler der Kategorie “sonstige Fehler” (siehe Abbildung 4). Hier wurden insgesamt mindestens 34 Fehler behoben.
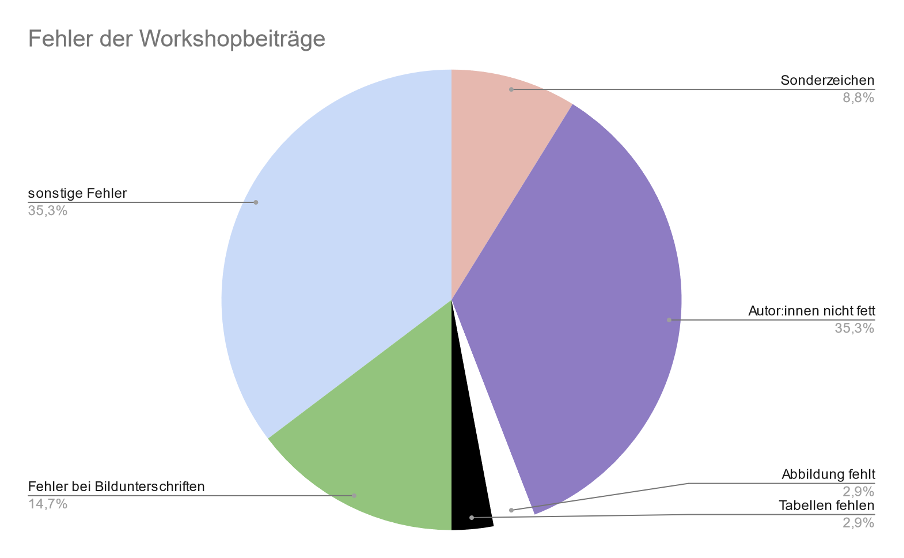{kind=link}
Abbildung 4: Fehleraufteilung der Workshopbeiträge.
VorträgeInsgesamt wurden 43 Vorträge angenommen. Von diesen hatten zwölf Beiträge Sonderzeichenfehler, sechs Beiträge hatten Fehler der Kategorie “sonstige Fehler”, zwei Beiträge hatten fehlerhafte Bildunterschriften und in einem Beitrag waren die Namen der Autor:innen in der Bibliographie nicht fettgedruckt. In keinem der Beiträge fehlten nach der automatischen Generierung der PDFs die Abbildungen oder Tabellen (siehe Abbildung 5).
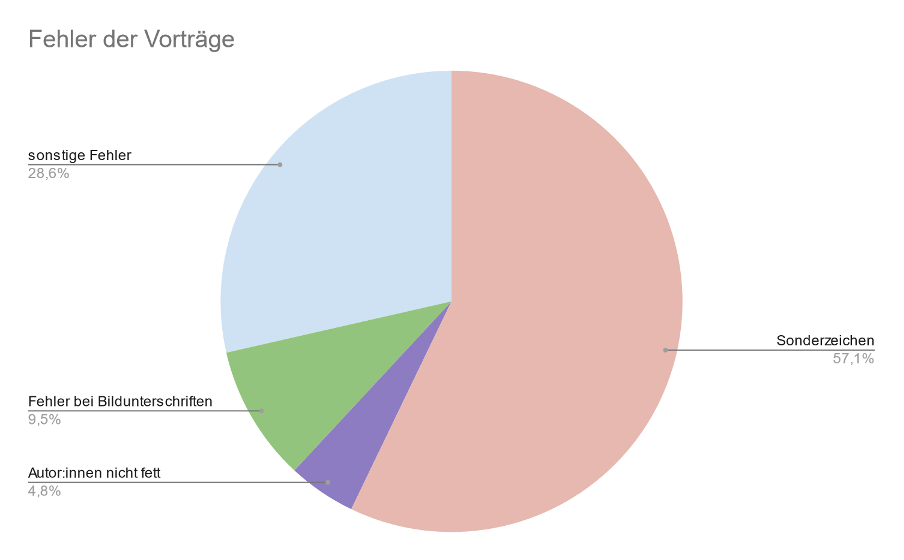{kind=link}
Abbildung 5: Fehleraufteilung der Vorträge.
Doctoral ConsortiumFür das Doctoral Consortium wurden elf Beiträge angenommen. Zwei von diesen Beiträgen hatten fehlerhafte Sonderzeichen, bei sieben Beiträgen waren die Autor:innennamen in der Bibliographie nicht fettgedruckt, bei einem Beitrag fehlten Abbildungen und bei einem Beitrag gab es einen Fehler in der Bildunterschrift. Fehlende Tabellen traten bei dieser Beitragskategorie nicht auf, wohingegen jeder Beitrag einen Fehler der Kategorie “sonstige Fehler” hatte (siehe Abbildung 6).
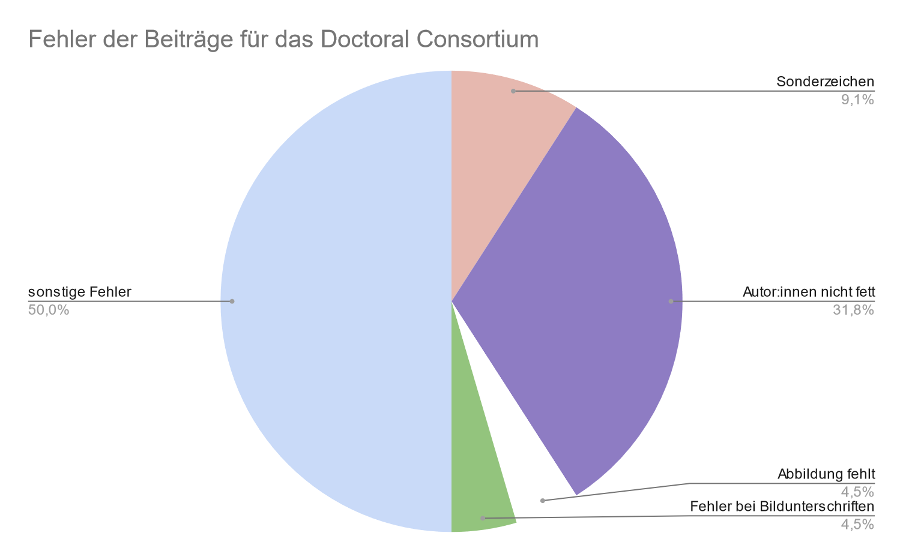{kind=link}
Abbildung 6: Fehlerverteilung bei den Beiträgen des Doctoral Consortiums.
Korrektur der FehlerBei der Korrektur der Fehler waren sowohl Mitarbeiter:innen und Hilfskräfte der Universität Passau als auch des DHd Data Stewards involviert. Nach einer Unterweisung, worauf bei der Korrektur zu achten ist, die auf den Erfahrungen der Vorjahre basierte, wurden die Beitragskategorien auf verschiedene Personen aufgeteilt und die Beiträge wurden mehrmals auf Fehler untersucht und korrigiert.
Bereits bekannte Fehler, wie die der Sonderzeichen, falsch formatierten Autor:innennamen, fehlenden Abbildungen und Tabellen sowie Fehler in der Formatierung der Bildunterschriften konnten schnell erkannt und korrigiert werden.
Weil die Kategorie “sonstige Fehler” eine offene Kategorie ist, in der bisher noch nicht bekannte Fehler verzeichnet wurden, wurde dort alles aufgenommen, was ungewöhnlich erschien. Da unterschiedliche Personen unterschiedliche Beiträge bearbeiteten, wurde individuell entschieden, was als Fehler aufgenommen wurde und was nicht. Diese Fehler wurden gemeinsam besprochen und manche dieser Fehler wurden als korrekturwürdig eingeordnet, andere wiederum nicht. Dies führte bei manchen Fällen zu doppelter Arbeit, da schon korrigierte Beiträge nochmals bearbeitet werden mussten, je nachdem ob ein Fehler bereits als solcher gewertet wurde, bevor er offiziell im Plenum als solcher deklariert wurde. Als Beispiel hierfür kann der vergrößerte Zeilenabstand genannt werden, der bei manchen Beiträgen entstand, wenn Fußnoten in der Zeile vorhanden waren. Dieser Fehler wurde bspw. automatisiert korrigiert, weshalb hierzu keine Statistik existiert.
Alle Beiträge wurden dreimal auf Fehler überprüft, bevor sie auf Zenodo hochgeladen und veröffentlicht wurden.
FazitBei der DHd Jahreskonferenz 2024, die von der Universität Passau ausgerichtet wurde, wurden 144 Beiträge in den Kategorien Poster, Panels, Workshops, Vorträge und Doctoral Consortium angenommen. Diese Beiträge wurden mehrmals auf Fehler überprüft, bevor sie auf Zenodo hochgeladen und publiziert wurden. Insgesamt wurden mindestens 213 Fehler korrigiert, wobei diese Zahl höher angenommen werden muss, da jeder Beitrag, der einen oder mehrere Fehler einer Kategorie beinhaltete, nur einmal in der jeweiligen Kategorie gezählt wurde.
Bereits bekannte Fehler wurden effizient erkannt und behoben. Fehler der Gruppe “sonstige Fehler” wurden nach Auffinden gemeinsam evaluiert und je nach Häufigkeit und Auswirkungen auf die PDF-Datei individuell als zu korrigierender Fehler gewertet.
Grundsätzlich verlief der Prozess gut, kann aber dennoch verbessert werden. Eine regelmäßige Auswertung der Kategorie “sonstige Fehler” und die Erweiterung der Liste schon bekannter Fehler kann zu einem gezielteren Korrekturansatz führen, wenn die Korrigierenden wissen, worauf geachtet werden muss.
Zudem wäre eine standardisierte und detailliertere Art der Fehlerdokumentation während der Korrektur hilfreich, um genauere Auswertungen zu erstellen.
Eine mögliche Option, um Fehler in den TEI-XML-Versionen der Beiträge zu vermeiden, ist die Einschränkung von Formatierungsmöglichkeiten für die Autor:innen. Dies könnte beispielsweise durch die Etablierung eines alternativen Tools zur Erstellung von Beiträgen zu DHd Jahreskonferenzen erreicht werden. Ein potenzieller Kandidat hierfür stellt der FidusWriter[5] da, der sich diesbezüglich aktuell in der Evaluierungs- und Anpassungsphase befindet.
ReferenzenHelling, Patrick, Anke Debeller und Rebekka Borges: „Konferenzbeiträge strategisch publizieren. Automatisierte Workflows zur individuellen Veröffentlichung von Konferenzbeiträgen am Beispiel des Verbands Digital Humanities im deutschsprachigen Raum e.V.“ in O-Bib. 2022a. Das Offene Bibliotheksjournal / Herausgeber VDB 9(3), 1-17. DOI: https://doi.org/10.5282/o-bib/5835.
Helling, Patrick, Rebekka Borges, Ingo Börner, Anna Busch, Fabian Cremer, Anke Debbeler, Henning Gebhard, Harald Lordick und Timo Steyer: “Der DHd-Verband und seine Abstracts – Betrachtungen des Einreichungsprozesses zu DHd-Jahrestagungen”, DHd-Blog. 2022b. Online: https://dhd-blog.org/?p=18599 (letzter Zugriff 21.05.2024).
[1] https://dhd2024.dig-hum.de, letzter Zugriff 21.05.2024.
[2] https://www.conftool.net/de/startseite.html, letzter Zugriff 24.04.2024.
[3] https://github.com/ADHO/dhconvalidator, letzter Zugriff 21.05.2024.
[4] https://github.com/PatrickHelling/DHd2022_BoA_separated, https://github.com/reborg789/zenodup, https://github.com/cceh/zenodup, letzter Zugriff 24.04.2024.
[5] https://www.fiduswriter.org/, letzter Zugriff 21.05.2024.
27.06.: Online-Vorträge von Tatiana Bessonova (Trier) und Vivien Wolter (Trier) im Rahmen des TCDH-Forschungskolloquiums
Am 27.06.2024 finden im Rahmen des TCDH-Forschungskolloquiums erneut zwei Vorträge statt:
Tatiana Bessonova (Trier): „Lügen Sie bewusst oder haben Sie nicht recherchiert?“: eine Analyse der Reaktionen auf die Beiträge öffentlich-rechtlicher Medien zum Thema Verschwörungstheorien.
Vivien Wolter (Trier): Die (virtuellen) Bretter, die die Welt bedeuten: Digitale Theaterforschung trifft auf Inszenierungen von Schirachs ‚Terror‘.
Im Sommersemester 2024 setzen wir unsere Vortragsreihe im Rahmen des TCDH-Forschungskolloquiums wieder fort. Studierende, Mitarbeitende und Fellows des TCDH geben ebenso wie externe Kolleg:innen und Kooperationspartner spannende Einblicke in ihre Arbeit aus ganz unterschiedlichen Feldern der Digital Humanities: der Computational Literary Studies, der digitalen Lexikographie und der digitalen Pragmatik, der digitalen Theaterforschung und der digitalen Edition.
Das Forschungskolloquium findet von 16 bis 18 Uhr (c.t.) via Zoom statt: https://uni-trier.zoom-x.de/j/67058779378?pwd=UFZ4WjBwNWVEaWFLRzh0aWszWkRudz09
Sie sind herzlich eingeladen, teilzunehmen und mitzudiskutieren!
{kind=link}
Virtuelles DH-Kolloquium an der BBAW, 24.06.2024: „Vom anderen Geschlecht zu anderen Geschlechter. Jenseits der Banalität – Über die literaturwissenschaftliche Genderanalyse in historischen und modernen Klassikern.“
Im Rahmen des DH-Kolloquiums an der BBAW laden wir Sie herzlich zum nächsten Termin am Montag, den 24. Juni 2024, 16 Uhr c.t., ein (virtueller Raum: https://meet.gwdg.de/b/lou-eyn-nm6-t6b):
Marie Flüh (Uni Hamburg) und Mareike Schumacher (Uni Stuttgart)
In unserem Vortrag zeigen wir anhand von zwei Fallstudien, wie die Klassifikation von Genderaspekten in literarischen Texten mithilfe der Methoden der Computational Literary Studies umgesetzt werden kann. Ausgehend von der Frage, was typische Genderdarstellungen sind und wann diese brüchig werden, untersuchen wir unterschiedliche Korpora: Im Fokus dieses Vortrags steht sowohl ein historisches Korpus mit Texten, die von Simone de Beauvoir anlässlich ihrer Studie “Das andere Geschlecht” (1949) analysiert wurden, als auch ein zeitgenössisches Korpus mit den Romanen der Harry-Potter-Serie (1997–2000). Mit der analytische Reise vom “anderen Geschlecht” nach Hogwarts geben wir Einblicke in unser Forschungsprojekt m*w/DISKO und zeigen eine genre- und zeitunabhängige Überrepräsentation männlicher Figuren-Referenzen. Dieser steht ein kleinerer Teil “anderer” Genderrepräsentationen gegenüber, die nicht ausschließlich als weiblich klassifiziert werden können. Anstelle einer binären Darstellung von Gender offenbart sich so ein aus mindestens drei Komponenten bestehendes “Gegengewicht” aus weiblichen, neutralen und diversen Figuren-Referenzen.
***
Die Veranstaltung findet virtuell statt; eine Anmeldung ist nicht notwendig. Zum Termin ist der virtuelle Konferenzrraum über den Link https://meet.gwdg.de/b/lou-eyn-nm6-t6b erreichbar. Wir möchten Sie bitten, bei Eintritt in den Raum Mikrofon und Kamera zu deaktivieren. Nach Beginn der Diskussion können Wortmeldungen durch das Aktivieren der Kamera signalisiert werden.
Der Fokus der Veranstaltung liegt sowohl auf praxisnahen Themen und konkreten Anwendungsbeispielen als auch auf der kritischen Reflexion digitaler geisteswissenschaftlicher Forschung. Weitere Informationen finden Sie auf der Website der BBAW.
10 Jahre RIDE – still enjoying the ride
Genau vor 10 Jahren, am 20. Juni 2014, erschien die erste Ausgabe der Rezensionszeitschrift RIDE – A Review Journal for Digital Editions and Resources, herausgegeben vom Institut für Dokumentologie und Editorik (IDE). Während wir den 10ten Geburtstag auf Mastodon im Fediverse von unserem IDE-Account unter dem Hashtag #10YearsRIDE feieren, wurde der Launch der digitalen Zeitschrift damals u. a. auf Twitter mit einem eher unscheinbaren Post (siehe Abb. 1) beworben. So manch einer fragte sich schon damals, wie man RIDE eigentlich ausspricht: /ri:de/ (Deutsch) oder /raɪd/ (Englisch)? Für die aufmerksamen Leser:innen werden wir das Geheimnis am Ende dieses Posts lüften.
{kind=link}
Abb. 1: Der Tweet zum RIDE-Launch.
RIDE wurde vom IDE ins Leben gerufen, um ein Forum zur Besprechung digitaler Editionen zu schaffen, einen Beitrag zur Qualitätssicherung zu leisten sowie die gängige Praxis zu verbessern und die zukünftige Entwicklung voranzutreiben.[1] Digitale Editionen wurden und werden[2] von traditionellen Rezensionsorganen meist übergangen und damit in den Fachwissenschaften kaum wahrgenommen. Dies wiederum führt dazu, dass den Ersteller:innen digitaler Editionen – von Editor:innen über Datenmodellierer:innen bis hin zu Softwareentwickler:innen – die Anerkennung ihrer Leistungen seitens der Fachwissenschaften oftmals verwehrt bleibt. Um dem entgegenzuwirken, sollte mit RIDE ein interdisziplinäres Austauschforum entstehen, in dem digitale Forschungsressourcen in ihrer Gesamtheit rezensiert werden, d. h. sowohl aus fachlich-inhaltlicher als auch und vor allem aus methodisch-technischer Perspektive.
Stand heute (Juni 2024) wurden in RIDE insgesamt 97 digitale Ressourcen in 18 Issues rezensiert. Ein Großteil der Rezensionen, 65 an der Zahl, ist digitalen Editionen gewidmet. Weitere 20 Rezensionen besprechen Textsammlungen (seit 2017) und bislang 12 Rezensionen nehmen »Tools und Arbeitsumgebungen für digitale Editionen« (seit 2022) in den Blick (Abb. 2). In der Sparte »Editionen« gibt es mittlerweile außerdem Themenausgaben: zwei Issues zu Briefeditionen und zwei Issues mit dem Schwerpunkt auf der Umsetzung der FAIR-Prinzipien. Derzeit liegen etwa zwei Drittel der Rezensionen auf Englisch und ein Drittel auf Deutsch vor, außerdem sind zwei Rezensionen in Französisch und eine in Italienisch verfasst (Abb. 3). Für alle drei Rezensionssparten – digitale Editionen, Textsammlungen und Tools – gibt es vom IDE erstellte Kriterienkataloge[3] zur Besprechung der jeweiligen Ressourcen, die die Rezensent:innen bei der Begutachtung unterstützen und als Leitfaden dienen sollen. Durch verschiedene Rückmeldungen aus der Community wissen wir, dass die Kriterienkataloge mittlerweile nicht nur zur Begutachtung in RIDE, sondern auch bei der Planung und Entwicklung neuer Ressourcen als best-practice-Leitfaden zum Einsatz kommen.[4]
{kind=link}
Abb. 2 / 3: Anzahl der Artikel pro Rezensionssparte (li.); Sprachen der Rezensionen (re.).
Durch die zunehmende Etablierung von RIDE hat sich der Aufwand des Betriebs und der Weiterentwicklung der Zeitschrift über die Jahre vervielfacht. Initial von einem Managing Editor geführt und zwischenzeitlich von einem Zweier-Team übernommen, umfasst das Management Team aus dem IDE-Kreis derzeit drei Personen.[5] Während die Herausgeber:innen der Issues in den ersten Jahren ausschließlich IDE-Mitglieder waren, planen und publizieren mittlerweile auch Gastherausgeber:innen ganze Issues.[6] Für bestimmte redaktionelle (u. a. Proof Reading) und technische Tasks, packt außerdem das ganze IDE regelmäßig mit an.
In RIDE besteht jede Rezension aus dem eigentlichen Rezensionstext und einem Factsheet. Letzteres ist ein Fragebogen mit weitgehend formalisierten Antwortmöglichkeiten, damit die rezensierten Ressourcen einfacher miteinander vergleichbar sind.[7] Gleichzeitig ermöglichen die erhobenen Daten einen Überblick, was bereits in RIDE rezensiert wurde, beispielsweise aus welchen Epochen und Disziplinen die begutachteten Editionsprojekte stammen (Abb. 4 und 5). Das Fächerspektrum in RIDE umfasst nahezu alle geisteswissenschaftlichen (textbezogenen) Disziplinen. Allerdings wird auch deutlich, dass trotz der interdisziplinären Anlage der Zeitschrift ein Großteil der rezensierten Editionen und Textsammlungen fachlich in den Literaturwissenschaften und zeitlich in der Moderne zu verorten ist.[8]
{kind=link}
Abb. 4 / 5: Epochenzugehörigkeit (li.) und Disziplinzugehörigkeit (re.) [9] der rezensierten Ressourcen.
Die Daten der Factsheets sind auch jenseits ihrer Rolle für die Rezensionen interessant, zum Beispiel als Grundlage, um (spartenübergreifend) Unterschiede und allgemeine Tendenzen hinsichtlich der Rezensionsobjekte zu ermitteln.[10] So bilden etwa Editionen, was die Offenheit der Daten bzw. des Quellcodes angeht, unter den drei Ressourcentypen das Schlusslicht, während die rezensierten Textsammlungen anteilig häufiger auf offene Daten und die rezensierten Tools sogar überwiegend auf offenen Source Code setzen (Abb. 6). Eine mögliche Erklärung hierfür ist, dass Editionen vor allem ›klassisch‹ über das Graphical User Interface rezipiert werden, während Textsammlungen stärker den Charakter eines Datensets haben. Editionstools hingegen funktionieren selten nach dem Prinzip Plug-and-Play, sondern müssen meist projektspezifisch angepasst werden, wofür offener Quellcode die Voraussetzung ist.
{kind=link}
Abb. 6 / 7: Offenheit der Daten bzw. des Quellcodes (li.) und Vorhandensein von Zitationsvorschlägen (re.) (jeweils anteilig pro Sparte).
Ein umgekehrtes Bild zeigt sich bei der Frage nach der Zitierbarkeit der Ressourcentypen (Abb. 7): In den rezensierten Editionen haben sich Zitierempfehlungen weitestgehend durchgesetzt, denn Referenzierbarkeit von Text ist schließlich ein Kernanliegen von Editionen. Das Schlusslicht bilden hier die Tools. Dort scheinen sich Zitationsstandards oder Zitierhilfen noch nicht durchgesetzt oder etabliert zu haben.
In anderen Kontexten haben wir bereits ausführlich über Ziele und Methoden von RIDE berichtet und geschrieben,[11] daher möchten wir anlässlich des zehnjährigen Jubiläums hier einen Einblick in die Arbeit geben, die täglich hinter den Kulissen passiert und die viel zu selten sichtbar wird. Dazu zählt u.a.: Autor:innen suchen, Artikel intern begutachten und mit hilfreichen Kommentaren zur Überarbeitung versehen, Peer Reviewer:innen suchen, die Rezensionen für die Publikation formatieren und konvertieren, verschiedene Publikationsformate generieren (XML/TEI, HTML, PDF), die Verfügbarkeit und Archivierung der Artikel sichern (u. a. über DOI, APIs), die Zeitschriftenbände bewerben. Zu den langfristigen Aufgaben zählen u. a. die Pflege und Weiterentwicklung des XML-Schemas für die Reviews und die Weiterentwicklung von Skripten und Routinen zur Verarbeitung der Daten für die Publikation. Auch der Server, auf dem die WordPress-Instanz von RIDE läuft, muss regelmäßig gewartet werden und die eXist-db-Instanz, die wir für einige Funktionen nutzen, braucht regelmäßig ein Upgrade auf eine neuere Version.
{kind=link}
Abb. 8: Das RIDE-Management-Team gewinnt den dritten Platz beim Posterwettbewerb der DHd2022 (Tweet).
Abgesehen von den herausgeberischen und den redaktionellen-technischen Tasks kümmern wir uns um die wissenschaftliche Etablierung und Sichtbarkeit der Zeitschrift. Beispielsweise hat RIDE erst kürzlich das Open Access-Seal der Directory of Open Access Journals (DOAJ) erhalten und wird demnächst in die Scopus-Datenbank aufgenommen. Schließlich ist auch die Dissemination unserer Arbeit im nationalen und internationalen Kontext ein wichtiger Teil unserer Mission, um das Thema »Qualitätssicherung digitaler Forschungsressourcen« in der Community präsent zu halten. Gleichzeitig steigern wir so die Bekanntheit von RIDE und können neue Rezensent:innen gewinnen. Fast alles, was wir für RIDE leisten, passiert ehrenamtlich und jenseits unserer Lohnarbeit, oft in den Abendstunden oder am Wochenende. Würdigungen unserer Arbeit, wie etwa der dritte Platz für unseren Beitrag beim Posterwettbewerb der DHd2022, freuen uns daher natürlich besonders (Abb. 8).
{kind=link}
Abb. 9: Internes Issue-Board des Herausgeber:innenteams.
Alle anfallenden Arbeiten für RIDE koordinieren und organisieren wir seit einiger Zeit in internen GitHub-Repositorien und nutzen dafür Issues, Project Board und Wiki (Abb. 9). Da wir RIDE möglichst offen gestalten möchten, stehen nicht nur die Rezensionsdaten, sondern auch einige Skripte, die im Publikationsprozess zum Einsatz kommen, über öffentliche GitHub-Repositorien und über Zenodo zur Verfügung.[12] Auch wenn es heutzutage digitale Arbeitsmittel braucht, um die Herausgabe einer Zeitschrift zu koordinieren, sollte nicht unerwähnt bleiben, dass wir eigentlich am liebsten in schummrigen Kneipen über Rezensionen und Digital Humanities diskutieren und Zukunftspläne für RIDE schmieden (Abb. 10 und 11).
{kind=link}
Abb. 10: Launch von RIDE 2014 in der legendären Bar Celentano, Köln (Tweet).
{kind=link}
Abb. 11: Vorbereitung des Launches der Sparte »Text Collections«, Elektra Bar, Köln (Tweet).
Die kontinuierliche Produktion von Bänden, die Weiterentwicklung der Zeitschrift auf verschiedenen Ebenen und der Betrieb der technischen Infrastruktur erfordern erhebliche (Wo|Man)-Power. RIDE ist ein Gemeinschaftsprojekt des IDEs und ohne die vielen Schultern seiner Mitglieder nicht zu stemmen. Daneben sind wir auf die Mitarbeit der Community angewiesen: auf die Autor:innen, die sich die Zeit nehmen, digitale Ressourcen genauestens unter die Lupe zu nehmen und teilweise auch mehrmalige Überarbeitungen ihrer Beiträge in Kauf nehmen; auf die Gast-Herausgeber:innen, die unsere Arbeit mit eigenen Bänden gewissenhaft fortführen und gleichzeitig neue Impulse setzen, und auf unser Editorial Board, das uns bei jedweden Problemen spontan unterstützt. Last but not least können wir auf ein Netzwerk an Peer-Reviewer:innen zählen, dank derer wir nach höchsten wissenschaftlichen Qualitätsstandards ein ›international peer-reviewed journal‹ publizieren können und die wertvolles Feedback zu den Rezensionen liefern. Ihnen allen möchten wir an dieser Stelle unseren herzlichsten Dank aussprechen!
Schließlich möchten wir aber auch den Leser:innen danken. Wir haben im Laufe der Jahre immer wieder wertvolles Feedback erhalten, was zur Entwicklung und Verbesserung von RIDE beigetragen hat. Deshalb lösen wir nun auch endlich das Rätsel um die Aussprache: RIDE ist natürlich Lateinisch /ri:de/: »ridere« = »lachen«. Und damit verabschieden wir uns fröhlich lachend, freuen uns auf weitere 10 Jahre RIDE und switchen zum Schluss doch noch mal ins Englische für das allseits bekannte und beliebte:
Enjoy the RIDE!
Die Mitglieder des Instituts für Dokumentologie und Editorik
***
[1] Siehe Philipp Steinkrüger, Ulrike Henny-Krahmer, Frederike Neuber und die Mitglieder der IDE, Editorial, März 2021, https://ride.i-d-e.de/about/editorial/.
[2] Siehe beispielsweise für Stichproben zur Rezension digitaler Forschungsressourcen in geschichtswissenschaftlichen Rezensionsorganen, Frederike Neuber und Patrick Sahle, Nach den Büchern: Rezensionen digitaler Forschungsressourcen, H-Soz&Kult 2022, https://www.hsozkult.de/debate/id/fddebate-132457; für eine fachlich engere Untersuchung Colleen Seidel, Digitale Forschung und Wissenschaftskommunikation – der Fall der mediävistischen Zeitschriften, DH@BUW 2022, https://dhbuw.hypotheses.org/319. Bezeichnend ist außerdem, dass selbst digitale Rezensionsplattformen wie Sehepunkte fast nur gedruckten Beiträgen ein Forum geben.
[3] Patrick Sahle; in Zusammenarbeit mit Georg Vogeler und den Mitgliedern des IDE; Version 1.1, Juni 2014, http://www.i-d-e.de/publikationen/weitereschriften/kriterien-version-1-1/; Ulrike Henny-Krahmer und Frederike Neuber, in Zusammenarbeit mit den Mitgliedern des IDE; Version 1.0, Februar 2017, https://www.i-d-e.de/publikationen/weitereschriften/criteria-text-collections-version-1-0/; Anna-Maria Sichani und Elena Spadini, in Zusammenarbeit mit den Mitgliedern des IDE; Version 1.0, Dezember 2018, https://www.i-d-e.de/publikationen/weitereschriften/criteria-tools-version-1/.
[4]So heißt es etwa in Bezug auf den Kriterienkatalog zur Besprechung von Textsammlungen bei José Calvo Tello, The Novel in the Spanish Silver Age (3. Data: Texts and Metadata), https://doi.org/10.14361/9783839459256-005, 3.1.2: „Its usefulness is beyond the specific frame of this journal, constituting a remarkable check‐list for any new literary corpus.“
[5] 2014-19 Philipp Steinkrüger, 2019-22 Ulrike Henny-Krahmer und Frederike Neuber, ab 2022 zusammen mit Martina Scholger.
[6] Auf Initiative von Anna-Maria Sichani und Elena Spadini wurde die Sparte „Tools and Environments“ eröffnet, die FAIR-Bände erscheinen in Kooperation mit dem NFDI-Konsortium Text+ und unter Beteiligung von dessen Mitarbeiter:innen (bisher Tessa Gegnagel und Daniela Schulz)..
[7] Zur rezensionsübergreifenden Vergleichbarkeit der Ressourcen bietet RIDE verschiedene Visualisierungen der Fragebögen für Editionen (https://ride.i-d-e.de/data/charts-scholarly-editions/) und Textsammlungen (https://ride.i-d-e.de/data/charts-text-collections/).
[8] Die rezensionsübergreifende Auswertung kann dabei hilfreich sein, solche ‚Ballungen‘ zu identifizieren und ihnen ggf. entgegenzuwirken, indem man gezielt Rezensent:innen für Ressourcen aus anderen Disziplinen und mit anderen epochalen Schwerpunkt zu gewinnen versucht.
[9] Die Antwortmöglichkeiten der Fragebögen zu Editionen und zu Textsammlungen unterscheiden sich leicht und wurden aufeinander gemappt. „Literary Studies / Philology“ im Editionenfragebogen entspricht „Literary Studies“ bei den Textsammlungen, die Kategorie „Musicology“ taucht nur im Editionenfragebogen auf, „Linguistics“ und „Archeology“ nur im Fragebogen der Textsammlungen.
[10] Siehe Claudia Resch, Digitale Editionen aus der Perspektive von Expert:innen und User:innen — Rezensionen der Zeitschrift RIDE im Meta-Review, in: Digitale Edition in Österreich / Digital Scholarly Edition in Austria, 2023, S. 37-54 (urn:nbn:de:hbz:38-704476).
[11] Siehe u. a. Neuber / Sahle 2022 (Anm. 2); Henny Ulrike, Reviewing von digitalen Editionen im Kontext der Evaluation digitaler Forschungsergebnisse, in: Digitale Metamorphose: Digital Humanities und Editionswissenschaft (hrsg. v. Roland S. Kamzelak and Timo Steyer), 2018. DOI: 10.17175/sb002_006;Markus Schnöpf, Evaluationskriterien für digitale Editionen und die reale Welt, in: HiN – Alexander Von Humboldt Im Netz 14(27), 69-76, DOI: 10.18443/182.
[12] Zur technischen Infrastruktur von RIDE siehe Henny-Krahmer, Ulrike; Frederike Neuber; Martina Scholger (2022): „Informationstechnologische Gedächtnisarbeit in der Rezensionszeitschrift RIDE“ [Poster]. In DHd 2022. Kulturen des digitalen Gedächtnisses. 8. Tagung des Verbands „Digital Humanities im deutschsprachigen Raum“, Potsdam. Zenodo. DOI: 10.5281/zenodo.6322571
Einladung an die DHd-Mitglieder zum Community Forum 05.07.2024
Liebe Mitglieder des DHd-Verbandes und Interessierte,
für unsere interdisziplinäre Community ist ein offener Austausch von großer Bedeutung. Während die jährliche Mitgliederversammlung bereits eine wichtige Rolle für unsere communityinterne Verständigung übernimmt, unterstützen wir als Vorstand weitere partizipative Angebote. Alle Mitglieder und Interessierte sind herzlich eingeladen, sich an den Diskussionen zu beteiligen sowie Themenvorschläge (info@dig-hum.de) einzureichen.
Das nächste virtuelle Community Forum findet am Freitag, dem 5. Juli 2024 von 14–15 Uhr statt. Gegenstand des Community Forums ist der im Dezember 2023 veröffentlichte Code of Conduct der Alliance of Digital Humanities Organizations (ADHO). Wir möchten das Community Forum nutzen, um mit Ihnen über mögliche Änderungsbedarfe für den DHd- Verband zu sprechen. Weitere Themen können wie immer zu Beginn des Community Forums vorgeschlagen werden.
Für das Community Forum werden wir das Videokonferenztool BigBlueButton nutzen. Wir möchten Sie bitten, sich mit vollständigem Namen anzumelden.
https://webroom.hrz.tu-chemnitz.de/gl/rab-rg7-psq-qcn
Wir freuen uns auf den Austausch mit Ihnen!
Mit freundlichen Grüßen
Rabea Kleymann (als Koordinatorin des Community Forums)
Anmeldung zur Tagung „Digital History & Citizen Science“ und zum 2. Community Forum NFDI4Memory eröffnet
Steintorcampus Halle (Saale), 18. sowie 19. bis 22. September 2024
https://www.geschichte.uni-halle.de/struktur/hist-data/dh_cs/
Die Tagung widmet sich mit einem reichhaltigen Programm wissenschaftlicher Vorträge und Diskussionsforen vielen Themen der Digitalen Geschichtswissenschaft an der Schnittstelle zwischen Wissenschaft und Citizen Science und Public History. Dabei spielen die Fragen des gemeinsamen Zugangs zu Quellen, methodischen Ansätzen und Fragestellungen ebenso eine Rolle wie Herausforderungen der digitalen Erschließung, Analyse und der langfristigen Archivierung von Citizen Science Nachlässen und Daten.
Begleitet werden diese Vorträge von vielfältigen und abwechslungsreichen Diskussionsrunden, Workshops und Projektvorstellungen. Kulturelle Angebote laden zum Kennenlernen und Mitmachen ein. Es finden sich viele Partner und Partnerinnen der digitalen Community zur Tagung ein, für die es zahlreiche Möglichkeiten des Kennenlernens und der Vernetzung geben wird. So können viele neue Impulse für gemeinsame Projekte und Ideen entstehen. Gleichzeitig feiern CompGen, Matricula und Archion ihre Jubiläumsveranstaltungen. Die Tagung „Digital History & Citizen Science“ findet vom 19. bis 22. September 2024 in Halle (Saale) statt. Zuvor veranstaltet das Konsortium NFDI4Memory das Community Forum NFDI4Memory am 18. September 2024. Sie sind herzlich zu allen Veranstaltungen eingeladen.
{kind=link}
Es handelt sich dabei um eine Gemeinschaftstagung der AG Digitale Geschichtswissenschaft des Verbands der Historiker und Historikerinnen Deutschlands, des Vereins für Computergenealogie, NFDI4Memory, Archion und ICARUS e.V., der Historischen Kommission Sachsen-Anhalt, des Instituts für Landesgeschichte (Sachsen-Anhalt) und des Landesheimatbundes Sachsen-Anhalt.
Anmeldung
Eine Anmeldung im ConfTool und für einzelne Veranstaltungen ist bis zum 29. August 2024 erforderlich. Dabei ist zunächst das Anlegen eines Benutzerkontos notwendig, um sich dann zur Tagung anzumelden. Bitte beachten Sie, dass wir aufgrund des Caterings eine Tagungsgebühr von 30 Euro für den mehrtägigen und 15 Euro für den eintägigen Besuch der Tagung erheben. Dafür stehen Ihnen während der Tagung Getränke und ein kleiner Imbiss zur Verfügung. Für Workshops und besondere Events sind zum Teil separate Anmeldungen im Rahmen der Tagung notwendig sind, weil zum Teil begrenzte Platzkapazitäten oder zusätzliche Gebühren bestehen. Podiumsdiskussionen, Vorträge und Projektpräsentationen stehen grundsätzlich allen Teilnehmenden frei.
Kontakt:
Dr. Katrin Moeller
Institut für Geschichte, Historisches Datenzentrum Sachsen-Anhalt
Emil-Abderhalden-Str. 26/27
06108 Halle (Saale)
digitalhistory@geschichte.uni-halle.de
CfP »Linked Open Data and Literary Studies« (19./20. November 2024, FU Berlin)
Die internationale Konferenz »Linked Open Data and Literary Studies« bietet Wissenschaftler*innen eine Plattform für den Austausch von Erkenntnissen, Methoden und bewährten Verfahren zur Nutzung von LOD-Technologien in der Literaturwissenschaft.
Immer mehr Institutionen, darunter Archive, Bibliotheken und Universitäten, reichern ihre Datensätze mit Metadaten an und veröffentlichen sie als Linked Open Data (LOD) im semantischen Web. Dieser Trend kommt auch den (digitalen) Geisteswissenschaften, einschließlich der Literaturwissenschaft, zugute und erleichtert die Einbeziehung metadatengestützter Ansätze in diesem Bereich. LOD können die Möglichkeiten zur Erforschung der globalen Dimensionen von Literatur erweitern.
Mögliche Themen der Konferenz:- literarische Metadaten und Knowledge Graphs,
- semantische Annotation literarischer Texte,
- LOD und unterrepräsentierte literarische Traditionen,
- Grenzen der Modellierung von Linked Data,
- LOD-Repositorien,
- Veröffentlichung und Abfrage von LOD,
- Visualisierungstechniken für die Erforschung literarischer Metadaten,
- Data Reconciliation,
- theoretische Grundlagen von LOD für die Literaturwissenschaft,
- Fallstudien über den Einsatz von LOD in der literaturwissenschaftlichen Projekten,
- Möglichkeiten und Grenzen der Nutzung von Linked Data für die Forschung zu literarischen Gattungen und Epochen,
- semantische Search & Recommendation Systems,
- KI-gesteuerte semantische Annotationen.
Bitte senden Sie Ihre Abstracts (200–300 Wörter) und Kurzbiografien an Frank Fischer (fr.fischer@fu-berlin.de) bis zum 24. Juni 2024.
Die Benachrichtigung über die Annahme erfolgt bis zum 8. Juli 2024. Für die Präsentationen ist eine Länge von etwa 20 Minuten geplant, gefolgt von einer 10-minütigen Diskussion.
Die Konferenz wird von der Research Area 5 des Exzellenzclusters 2020 »Temporal Communities« organisiert und findet am 19. und 20. November 2024 an der Freien Universität Berlin statt.
Der ausführliche (englischsprachige) Call for Papers findet sich auf der Homepage des Exzellenzclusters:
https://www.temporal-communities.de/calls/papers/cfp-open-data.html
Wissenschaft auf die Ohren – Workshop zu Formaten und Etablierung von Wissenschaftspodcasts
18.-19. Juli 2024 an der Fachhochschule Potsdam
Organisation und Konzeption: Dr. Jacqueline Klusik-Eckert, Prof. Dr. Ulrike Wuttke
Podcasts haben sich in den letzten Jahren als dynamisches Medium für die Wissenschaftskommunikation erwiesen. Sie bieten Wissenschaftler*innen, Projekten und Forschungsinstitutionen eine direkte, flexible und persönliche Methode, um komplexe Themen sowohl einem breiten Publikum als auch der eigenen Fachcommunity zugänglich zu machen. Komplexe Informationen werden in etablierten Formaten auf leicht verständliche Weise vermittelt. Die informelle und oft leichtgängigere Sprache der sogenannten Laberpodcasts schafft zudem eine Verbindung zwischen den Zuhörenden und den Sprechenden, die in traditionelleren Medien oft schwer zu erreichen ist. In einer Welt, in der die Zugänglichkeit von Wissenschaft und Forschung immer wichtiger wird, haben Podcasts ein hohes Potenzial für die Demokratisierung von Wissen. Als Open Science-Praktik der Wissenschaftskommunikation tragen sie dazu bei, den Zugang zu Wissen und Wissenschaft zu fördern und die Diskussion über wissenschaftliche Themen auch über akademische Kreise hinauszutragen.
Unser Workshop zielt darauf ab, eine Plattform für den Austausch zwischen aktiven Podcaster*innen und Vertreter*innen wissenschaftlichen Institutionen (Forschungseinrichtungen, Bibliotheken etc.) zu bieten, um Erfahrungen zu teilen, neue Ideen zu entwickeln und Forschung im Bereich Wissenschaftspodcasts zu initiieren. Im Mittelpunkt des Workshops soll interdisziplinäres Community Building rundum Wissenschaftspodcasts im Zeichen des fokussierten Austauschs zu den Schwerpunkten Formate und Etablierung als Medium der Wissenschaftskommunikation stehen.
Programm 18.07.2024, Donnerstag: Fokus Format 13:00 Uhr Begrüßung 13:30 Uhr Jonathan D. Geiger (Akademie der Wissenschaften und Literatur, Mainz), Lisa Kolodzie, Jascha Schmitz (HU Berlin), Mareike Schumacher (Universität Stuttgart): RaDiHum20 – Erfahrungen eines Community-Podcasts 14:00 Uhr Sharon Hundehege (FH Potsdam): Podcast aus dem Archiv 14:30 Uhr Ulrike Wuttke (FH Potsdam): From Global to Local? Perspektiven und Herausforderungen für eine Podcastreihe im Rahmen eines multimedialen Sammelbands 15:00 Uhr Pause 15:30 Uhr Mareike Schumacher (Universität Stuttgart), Melanie Seltmann (Humboldt-Universität zu Berlin), Ulrike Wuttke (Fachhochschule Potsdam): Potenziale von Podcasts für die Dissemination von Digital Humanities 16:00 Uhr Kreativsession: Formate für Wissenschaftspodcasts 18:00 Uhr Gemeinsames Pizzaessen 19:00 Uhr Kamingespräch im Campusgarten mit Tessa Gengnagel (Universität Köln) 19.07.2024, Freitag: Fokus Etablierung als Medium der Wissenschaftskommunikation 9:00 Uhr Start in den Tag 9:15 UhrImpulse Infrastrukturen und wissenschaftliche Datenbanken mit
Jakob Reuster (Bayerische Staatsbibliothek München, Fachinformationsdienst Ost-, Ostmittel- und Südosteuropa): Nachweis von wissenschaftlichen Podcasts mit Osteuropabezug im Forschungsportal osmikon
Stella Philipp (Sächsische Landesbibliothek – Staats- und Universitätsbibliothek Dresden): Infrastrukturen für Produktion und Nachweis von Wissenschaftspodcasts an der SLUB Dresden
Jens Kösters, Carolin Eisentraut, Matti Stöhr (TIB – Leibniz-Informationszentrum Technik und Naturwissenschaften: und Universitätsbibliothek): SciPAI: Zur Idee eines KI-gestützten Infrastrukturframeworks für Wissenschaftspodcasts
10:45 Uhr Pause 11:00 Uhr Alexander Winkler (digiS, dem Forschungs- und Kompetenzzentrum Digitalisierung Berlin): Podrot? Die Langzeitverfügbarkeit von Podcasts als Herausforderung 11:30 Uhr Jacqueline Klusik-Eckert (HHU Düsseldorf): Der Traum von einer All-in-One-Lösung? 12:00 Uhr Pause 13:00 Uhr Julia Panzer (Wissenschaft im Dialog): Wissen, was wirkt – Evaluation und Impact wissenschaftlicher Podcasts 13:30 Uhr Schreibsession: Nachhaltiges Wissenschaftspodcasting und die FAIR-Prinzipien 14:30 Uhr Abschied und Schluss
Es gibt auch einige Plätze für Teilnehmer*innen ohne eigenen Beitrag. Die Teilnahme ist kostenfrei, aus Kapazitätsgründen ist eine Anmeldung unter wisspod-workshop@listserv.dfn.de jedoch zwingend notwendig.
Die Anmeldedeadline ist der 11.07.2024. Wir benachrichtigen Sie so schnell wie möglich.
Tauche ein in Europas musikalisches Erbe mit dem WebPortal Polifonia
Polifonia ist ein gerade abgeschlossenes Forschungsprojekt, finanziert aus dem EU Horizon 2020
Programm, das nun seine Forschungsresultate einer breiten Öffentlichkeit zur Verfügung stellt.
Situiert zwischen Musikinformation- und dokumentation, Musikwissenschaft und neuen
semantischen Web Technologien, bietet das Polifonia Portal einen neuartigen Zugang zum
musikalischen kulturellen Erbe Europas.
Das musikalische Erbe Europas ist reichhaltig, es umfasst Bibliotheken von Noten,
Musikaufnahmen, Informationen über Musikveranstaltungen, über Komponisten, usw usf.. Vieles
davon ist bereits digitalisiert, und wird auch über das Internet angeboten: aber von
unterschiedlichen Anbietern, in unterschiedlichen Formaten, und mit unterschiedlichen
Zugangsbedingungen. Das Polifonia Portal ermöglicht eine völlig neue Art des Zugangs. Es
vereint Quellen ganz verschiedener Herkunft und ermöglicht es, in die Welt der Musik auf
unterschiedliche Weise einzutauchen. Das Projekt selbst hat bereits große Sammlungen (etwa
von niederländischen Volksliedern oder von französischen Musikbibliotheken) integriert, die nun
mit dem Portal erkundet werden können.
Eine herausragende Rolle für die künstliche Intelligenz
Ebenso wichtig wie das gegenwärtige Portal, sind die Technologien, die benutzt wurden um das
Portal aufzubauen. Diese sind als open source verfügbar, und ermöglichen es in Zukunft sowohl
weitere Sammlungen in das vorhandene Portal ein- und dadurch miteinander zu verbinden, als
auch ähnliche Portale für andere Inhalte zu gestalten.. Die technologische Basis von allem sind
sogenannte Wissensgraphen (knowledge graphs) und deren in Ontologien festgelegte
Wissensorganisationen. Künstliche Intelligenz wurde eingesetzt, um Lücken in der
Musikdokumentation zu schließen. Aber am Ende ist das Wichtigste, einem breiten Publikum
Musik auf neue Weise näher zu bringen, und neugierig darauf zu machen, wie Musik neu
erforscht und erfahren werden kann.
{kind=link}
Das Polifonia Portal, ein Webportal, lädt Nutzer zur Erkundung von fünf spezialisierten
Suchbereichen ein. Diese wurden basierend auf Nutzerstudien ausgewählt, um sowohl eine
effiziente gezielte Suche als auch eine mehr zufällige Erkundung des musikalischen Erbes
möglich zu machen. Automatische Vorschläge von Suchbegriffen (suggestions) und
Filteroptionen (categories) unterstützen die Verfeinerung der Recherche.
Um eine Suche durch verschiedenartige Bestände zu ermöglichen, müssen erst die
Informationen, die diese Bestände beschreiben, miteinander verbunden werden. Basierend auf
dieser aufwändigen Integrationsarbeit enthüllt das Portal dann vorher verborgene Verbindungen
und ermöglicht neuartige Erzählungen über Elemente und Ereignisse in der reichen europäischen
Musiklandschaft. Es bietet den Nutzern eine umfassende und vernetzte Sicht auf unser kulturelles
Erbe. Die Benutzererfahrung des Portals ist so gestaltet, dass sie zufällige Entdeckungen
begünstigt, anstatt bereits vorgegebene Pfade anzubieten.
Erste positive Berichte von Nutzern über solche zufälligen Entdeckungen lesen sich wie: „Das ist
ein wahr gewordener Traum, ich wusste nicht, dass es so ein Tool gibt. Eine Suche nach Punkrock
führte mich zu digitalisierten Comics über Rancid und Punk-Subkulturen”.
Hinter dem Portal steht die Gemeinschaftsarbeit von führenden Europäischen Universitäten,
Forschungsinstitutionen (der Università di Bologna, die Open University, die University of Galway,
die Meertens Instituut-KNAW, das King’s College London und das Centre National de la
Recherche Scientifique) mit Einrichtungen, die über grosse Musiksammlungen verfügen (das
italienische Ministero della Cultura, das französische Conservatoire National des Arts et Metiers,
und das Nederlands Instituut voor Beeld & Geluid). Das Portal basiert auf mehreren Datensätzen,
die von Polifonia-Partnern und darüber hinaus erstellt wurden, nämlich: musoW, MEETUPS,
CHILD, BELLS, MusicBO, ORGANS, FoNN, TUNES und Wikidata.
Dies ist bei weitem nicht alles, was dieses vierjährige Projekt hervorgebracht hat. Die Forschung
und Entwicklung im Rahmen der Arbeitspakete und der 10 Pilotprojekte umfasste auch die
Veröffentlichung von Open-Source-Software, Datensätzen und Ontologien, wie z. B.: Pitchcontext,
MELODY, Polifonia Knowledge Extractor, Polifonia Corpus Annotation, Sparql Anything, Polifonia
Corpus, CLEF, LHARP, FACETS, Frequently Occuring Patterns, TONALITIES, Roman Chord
Ontology, Music Meta, Jams Ontology, Roman Chord APIs, ChoCo, Polifonia Lexicon und MOZ.
Darüber hinaus wurden haptische Geräte für hörgeschädigte Zuhörer entwickelt und Experimente
mit „Deep Listening“ durchgeführt. Diese Ergebnisse stellen insgesamt den Höhepunkt der
Projektanstrengungen dar und sind als Teil des sogenannten ‘Ecosystem’, Polifonia-Ökosystems,
dokumentiert. Letzteres zielt daruf ab, Forschung und Innovation in den Musikwissenschaften,
den digitalen Geisteswissenschaften insgesamt voranzutreiben und zu einer Bewahrung des
Kulturerbes im digitalen Zeitalter beizutragen.
Web Portal
Hier gelangen Sie zum Web Portal:
https://polifonia.disi.unibo.it/portal/
Ecosystem
Polifonia-Daten, -Tools und
-Dokumentationen sind frei zugänglich und
können hier abgerufen werden:
https://polifonia-project.github.io/ecosystem/
Kontakt
Anfrage zum Webportal:
Marilena Daquino, Senior assistant professor,
Fachbereich Klassische Philologie und
Italianistik. Università di Bologna
<marilena.daquino2[@]unibo.it>
Untersuchung über das Ecosystem:
Enrico Daga, Senior Research Fellow
Fakultät für Wissenschaft, Technologie,
Ingenieurwesen und Mathematik. The Open
University
<enrico.daga[@]open.ac.uk>
Websites & socials
www: polifonia-project.eu
GitHuB: polifonia-project
LinkedIn: polifonia-h2020
X: @PolifoniaH2020
YouTube: @polifoniaplayingthesoundtr4703
Einladung zum Online-Vortrag am 13. Juni von Anna Traurig (Würzburg) im Rahmen des TCDH-Forschungskolloquiums
Im Rahmen des TCDH-Forschungskolloquiums im Sommersemester 2024 unter dem Motto „Perspektiven der Digital Humanities“ hält Anna Traurig (Würzburg) einen Vortrag zu: „William Lovell digital“. Ein Editions- und Buchprojekt.
Im Sommersemester 2024 setzen wir unsere Vortragsreihe im Rahmen des TCDH-Forschungskolloquiums wieder fort. Studierende, Mitarbeitende und Fellows des TCDH geben ebenso wie externe Kolleg:innen und Kooperationspartner spannende Einblicke in ihre Arbeit aus ganz unterschiedlichen Feldern der Digital Humanities: der Computational Literary Studies, der digitalen Lexikographie und der digitalen Pragmatik, der digitalen Theaterforschung und der digitalen Edition.
Das Forschungskolloquium findet von 16 bis 18 Uhr (c.t.) via Zoom statt: https://uni-trier.zoom-x.de/j/67058779378?pwd=UFZ4WjBwNWVEaWFLRzh0aWszWkRudz09
Sie sind herzlich eingeladen, teilzunehmen und mitzudiskutieren!
Wir freuen uns auf Sie!